前言
最近一年里,随着Tracktor++这类集成检测和多目标跟踪算法框架的出现,涌现了很多相关的多目标跟踪算法变种,基本都位列MOT Challeng榜单前列,包括刚刚开源的榜首CenterTrack。这里我就对集成检测和跟踪的框架进行分析,相关MOT和数据关联的基础知识可以去我的专栏查看,后期我也会针对基于深度学习的数据关联、ReID2MOT和SOT2MOT等进行专题介绍。
1.Detect to Track and Track to Detect(D&T)
作者:Christoph Feichtenhofer, Axel Pinz, Andrew Zisserman
备注信息:ICCV2017
当前的多目标跟踪算法主流是基于检测的框架,即Detection based Tracking(DBT),所以检测的质量对于跟踪的性能影响是很大的。那么在MOT Challenge上也分别设置了两种赛道,一种是采用官方提供的几种公共检测器的结果,即public赛道,一种是允许参赛者使用自己的检测器,即private赛道。
这篇D&T就属于private类跟踪框架,并初步将检测与跟踪框架进行了结合:
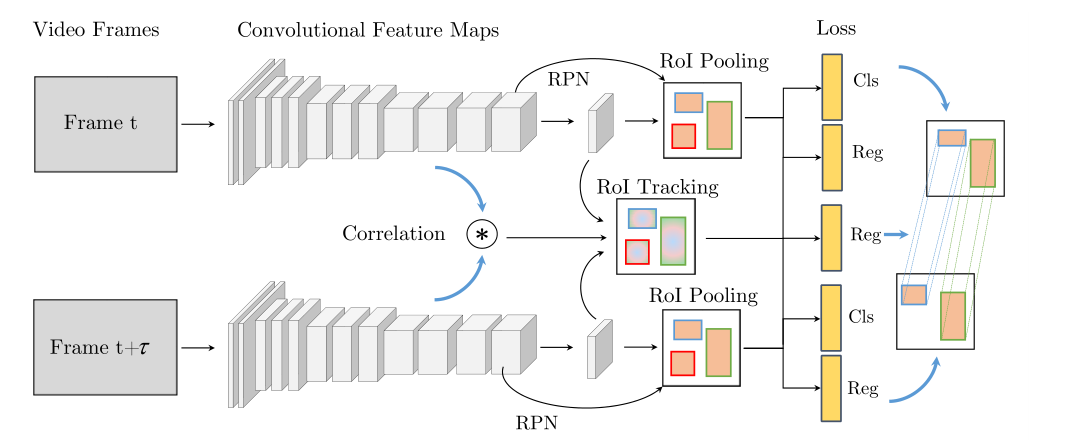
从图中可以清晰看到,作者通过改进版的R-FCN检测网络实现了主线的检测任务,然后基于两阶段目标检测的特点,将第一阶段所获得的多尺度特征图进行交互。这种方式借鉴了单目标跟踪中经典的Siamese网络框架,不同之处在于原本的Siamese网络做的是1:1的相关滤波,而D&T框架做的是n:n的相关滤波。其中两个分支中所包含的目标数量也是不定的,那么为什么作者要用R-FCN网络呢,可以发现,R-FCN的网络结构起到了很好的作用,正是因为其独特的position-sensitive ROI Pooling模块:
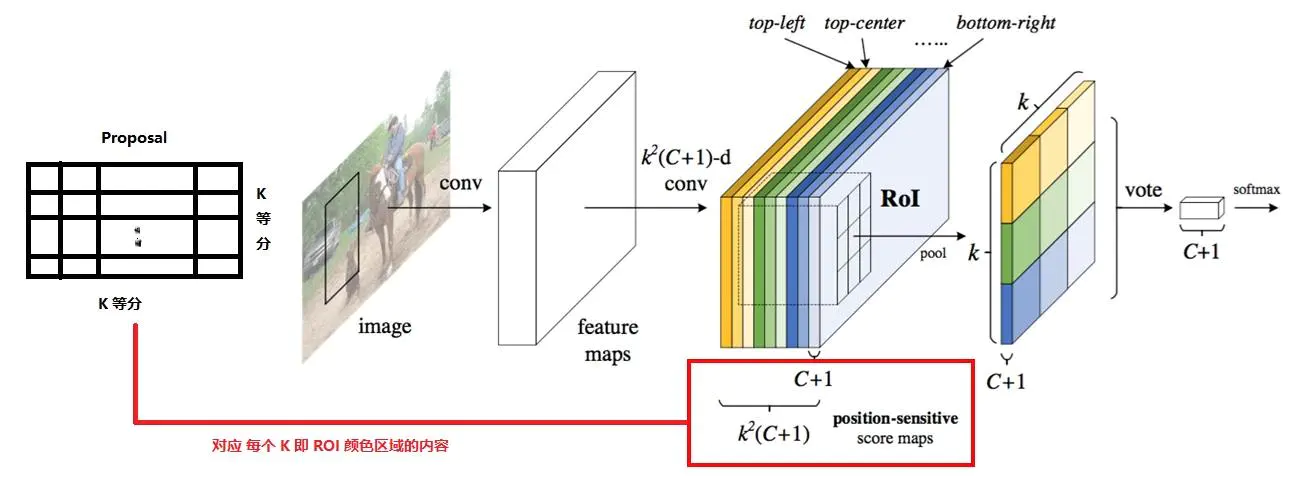
不同于传统两阶段目标检测框架利用全连接网络分支预测分类和回归的情况,R-FCN通过全卷积的方式将分类得分转化到特征图通道上,使得特征图保持了一定的平移不变性(这个可以看我之前的博客),有利于跟踪任务的相关滤波。那么这里D&T在传统目标检测的分类和回归任务上,增加了一个跟踪分支,作者巧妙地将跟踪任务转化成了预测相邻两帧各目标位置相对偏移量的回归任务。
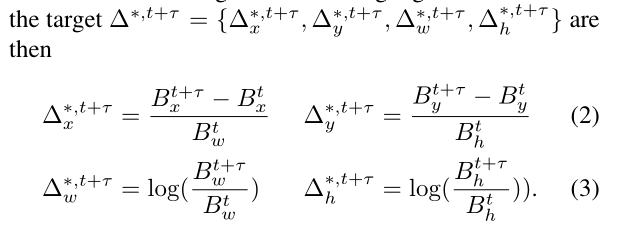
当然,跟踪分支只考虑与gt的IOU>0.5的预测框,并且目标要同时出现在这两帧。多任务损失函数如下:
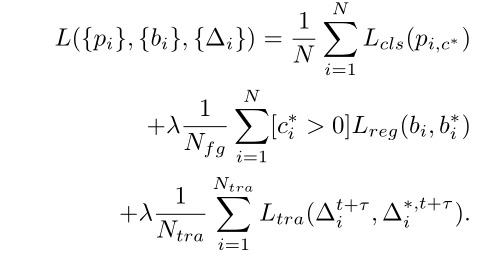
最后我们谈一下最重要的一点,如何做ROI Tracking,即在不丢失相对位置关系的前提下,执行多个区域的相关滤波:

提到相关滤波,我们可能容易想到单目标跟踪中的CF类传统方法,比如KCF(详细原理可以看我的解析)。KCF算法中就是通过循环移位的方式,利用相关滤波估计目标在图像中的位置变化。但是这种方式并不适合多目标的相关滤波,我们基于相邻两帧变化幅度不大的假设,更希望的是每块局部区域单独做类似于循环移位之类的操作。对此,作者借鉴了FlowNet的Corr操作,因为光流任务也是估计相邻帧像素的偏移量,所以用在这里很合适。
Corr的公式是:
可以看到,这里的滤波不是对卷积核的,而是将两幅特征图的多个kxk的区域分别做相关滤波,从而保持了相对位置。
最后对于多目标跟踪的部分,作者对于两个目标的连接代价设置如下:
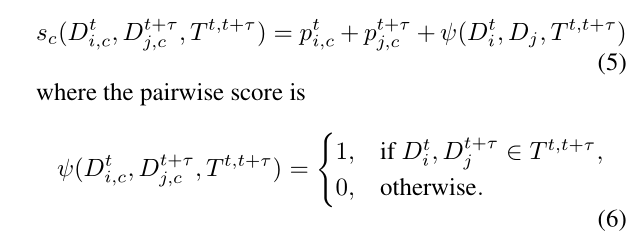
其中p表示的相邻两帧的检测置信度,最后一项指的是相邻两帧的目标框与预测到的位置的IOU>0.5时为1,否则为0。至此我们就可以得到跟踪预测位置和代价矩阵了,后面就是常规的多目标跟踪算法操作了。
2.Real-time multiple people tracking with deeply learned candidate selection and person re-identification(MOTDT)
作者:Long Chen, Haizhou Ai, Zijie Zhuang, Chong Shang
备注信息:ICME2018
这篇论文表面看上基于R-FCN检测框架的private多目标跟踪算法,不过与上一篇不同的是,作者只利用R-FCN对观测框进行进一步的前景/背景分类,即用于目标框的分类过滤,而且MOTDT将检测和跟踪框架分离了。作者的框架也是由现在多目标跟踪算法的通用模块组成的,即检测、外观模型和运动模型。这里我们就只关注他的算法流程:

从算法流程可以清晰地看到,MOTDT的流程是:
利用Kalman Filter完成目标的运动估计;
将观测框和跟踪框合并,并做NMS操作,其中每个目标框的置信度得到了修正:

这里面L表示的长度,通过上面两个公式,作者将检测置信度和跟踪轨迹置信度结合在一起了。
提取ReID特征,先基于ReID相似度进行匹配,再对剩余的利用IOU进行关联。
MOTDT这个算法框架很经典,对于后续的一些多目标跟踪算法也起到了启发作用。
3.Tracking without bells and whistles(Tracktor++)
作者:Philipp Bergmann,Tim Meinhardt,Laura Leal-Taixe
备注信息:ICCV2019,MOT15~17: 46.6, 56.2. 56.3 MOTA(public)
Tracktor++算法是去年出现的一类全新的联合检测和跟踪的框架,这类框架与MOTDT框架最大的不同在于,检测部分不仅仅用于前景和背景的进一步分类,还利用回归对目标进行了进一步修正,因此关于这类框架属于public还是private得争论也存在,这里我们就不做过多的讨论了。
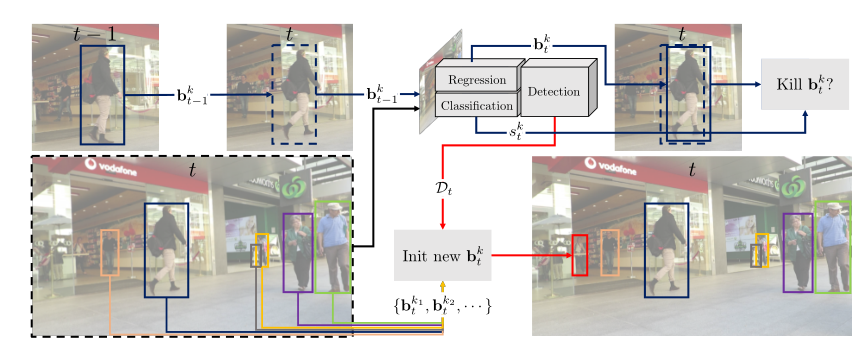
只要熟悉两阶段目标检测算法的应该都能理解这个算法,其核心在于利用跟踪框和观测框代替原有的RPN模块,从而得到真正的观测框,最后利用数据关联实现跟踪框和观测框的匹配。流程图如下:

有了检测模块的加持,自然对于检测质量进行了增强,所以效果也得到了大幅提升:
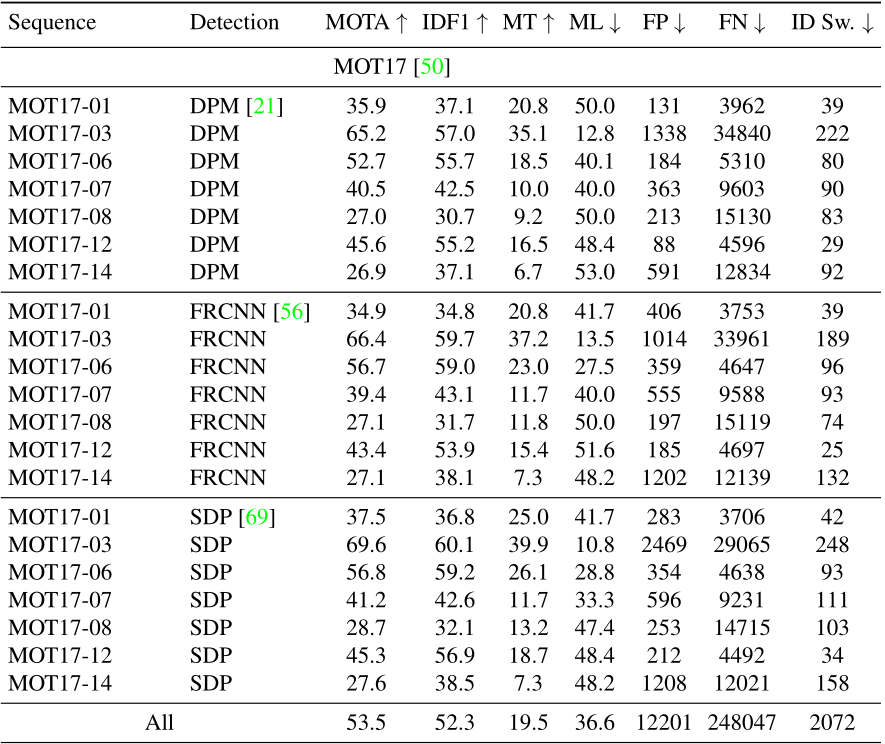
可以看到,DPM、FRCNN和SDP三种检测器输入下的性能差距不大,然而DPM检测器的性能是很差的,所以Tracktor++这类算法对于平衡检测输入的效果提升很大。
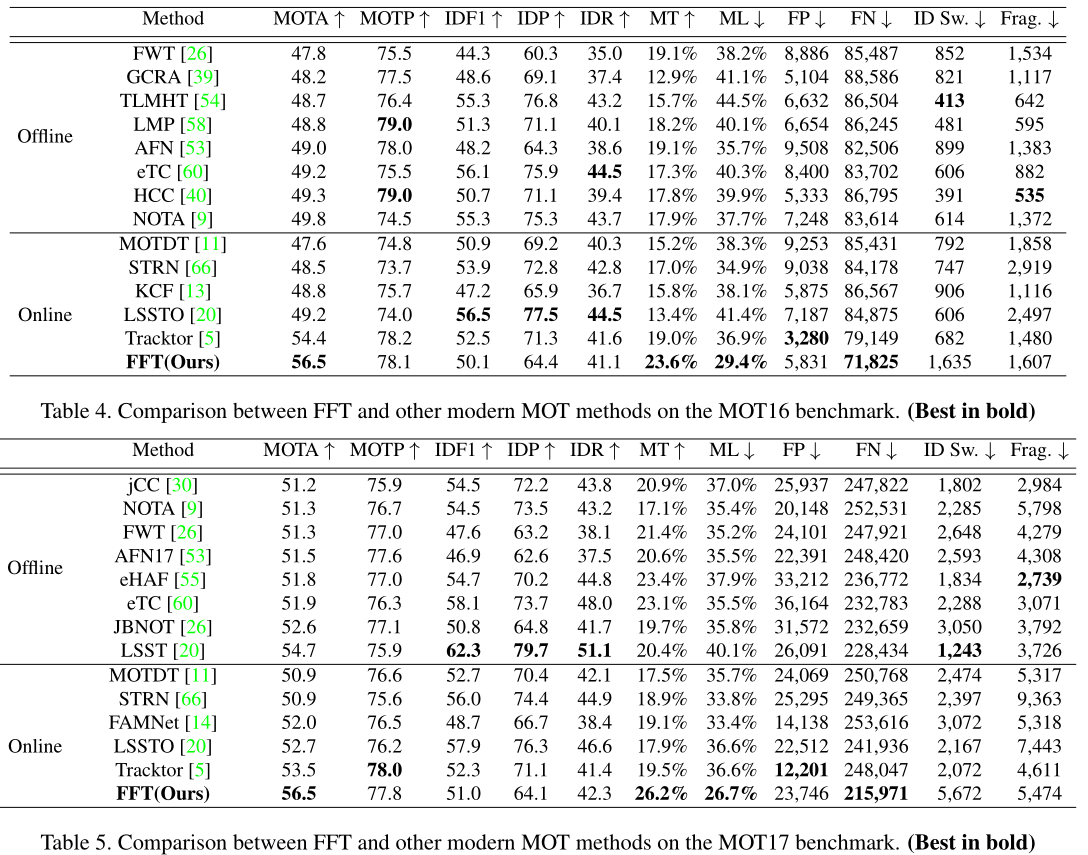
4.Multiple Object Tracking by Flowing and Fusing(FFT)
作者:Jimuyang Zhang, Sanping Zhou, Xin Chang, Fangbin Wan, Jinjun Wang, Yang Wu, Dong Huang
备注信息:MOT15~17: 46.3, 56.5. 56.5 MOTA(public)
这篇文章也是基于Tracktor++的模式,做了很直接的一步操作,即直接增加一个光流预测分支,将Tracktor++中的跟踪框+观测框变成了光流预测框+观测框
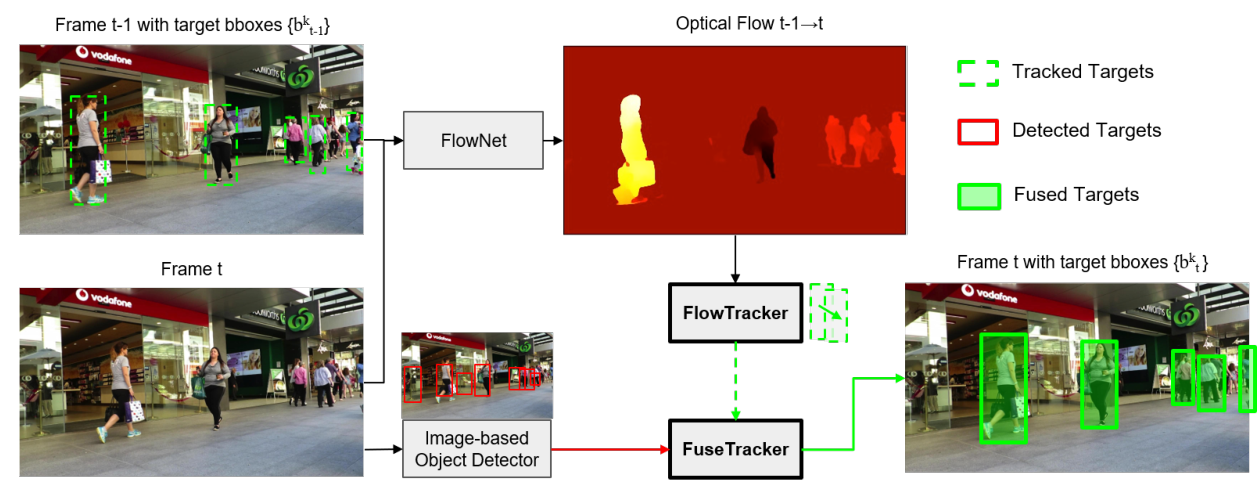
不过好处在于光流网络和Faster RCNN可以联合训练,在训练的时候RPN保留,不过从论文来看光流部分好像是固定权重的,其效果相对来说的确更好了:
5.Towards Real-Time Multi-Object Tracking(JDE)
作者:Zhongdao Wang,Liang Zheng,Yixuan Liu,Shengjin Wang
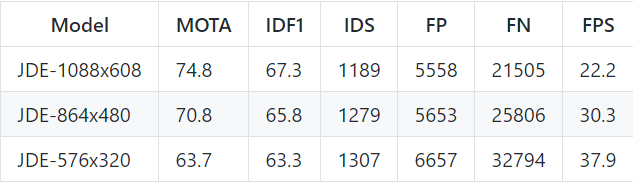
备注信息:MOT16 74.8 MOTA(private), 22FPS!!
JDE这篇跟这次的主题不是很相符,但是考虑到这也是近期比较热门的实时多目标跟踪算法,我们也一起讲。它的框架出发点是为了增加特征的复用性,基于检测算法(作者采用的是YOLOv3),在原本的分类和回归分支上增加了一个表观特征提取的分支。
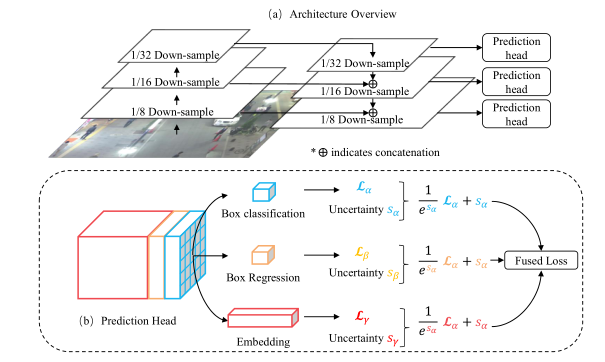
文中作者重点介绍了多任务网络框架的训练方式,首先分析了三种Loss:
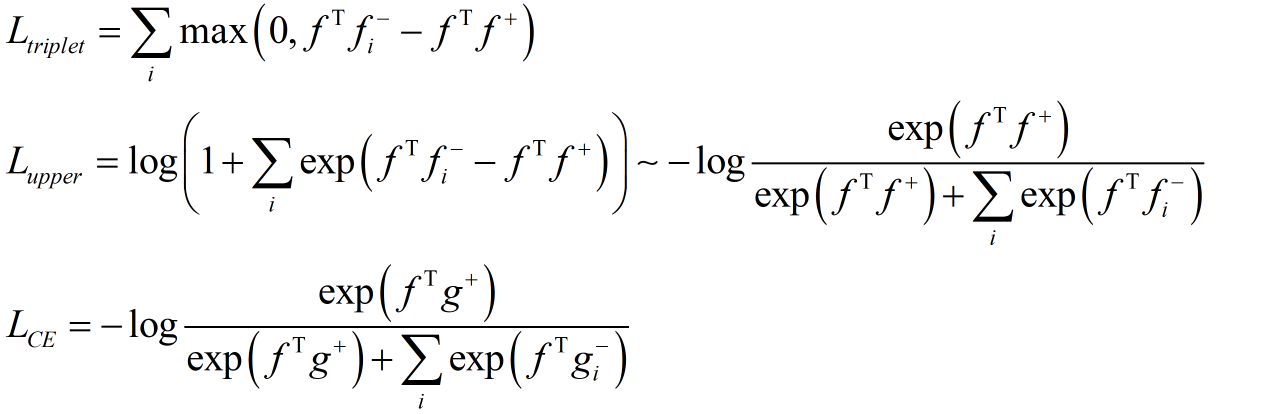
对于triplet loss,这个在表观模型的metric learning任务中很常见,作者采用了batch hard模式,并提出了triplet loss的上界,推导很简单,关键在于多的那个1。为了更好地跟交叉熵损失函数进行比较,作者将上界进行了平滑。那么区别就在于g,g表示的正负样本的权重。在交叉熵损失函数中,所有的负样本都会参与计算,然而在triplet loss中,负样本是采样出来的,所以:
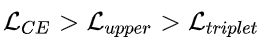
作者通过实验也论证了上面的结论,所以在metric learning中作者采用了交叉熵损失函数。最后关于各个任务的损失函数的权重,作者提出了一种自适应平衡的加权方式:
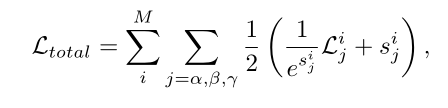
其中的s是一种度量不同任务下个体损失的不确定性因子,详细的原理可参见CVPR2018的《 Multi-task learning using uncertainty to weigh losses for scene geometry and semantics》关于方差不确定性对于多任务权重的影响分析。
效果和速度都很诱人~
6.Refinements in Motion and Appearance for Online Multi-Object Tracking(MIFT)
作者:Piao Huang, Shoudong Han, Jun Zhao, Donghaisheng Liu, HongweiWang, En Yu, and Alex ChiChung Kot
备注信息:MOT15~17: 60.1, 60.4, 48.1 MOTA(public)
这篇也是我们团队基于Tracktor++框架做的一个框架,主要关注的是运动模型、表观模型和数据关联部分的改进,由于某些原因,我这里不能细讲。代码会慢慢开源,暂时没有完全开源。
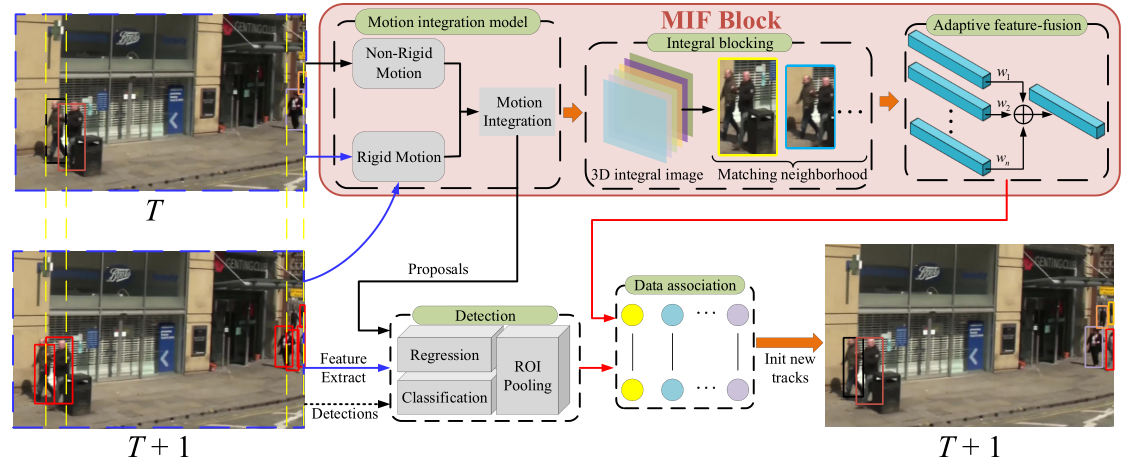
其中对于运动模型部分,我们将Kalman和ECC模型集成在一起,而不是将Kalman和ECC模型独立执行,实验证明融合的版本比分开的提升了1.4 MOTA。

对于表观模型,我们考虑到特征对齐的因素,做了一点小改进,结合可视度预测设计了多任务的表观模型:
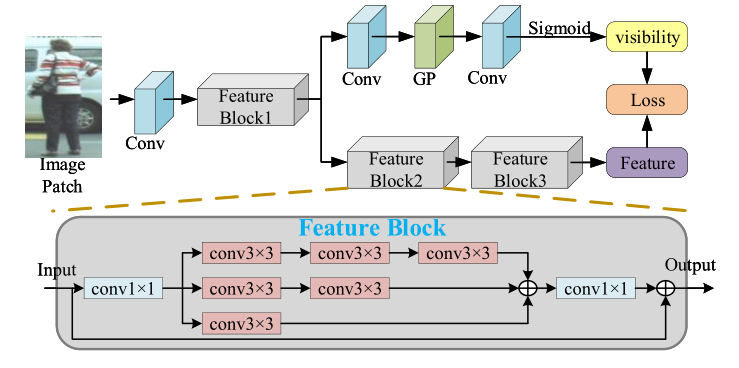
并在观测框和跟踪轨迹特征比对的时候,考虑了跟踪轨迹历史信息,来进行自适应加权:
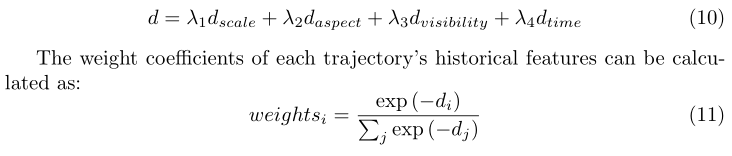
通过上面的分析,我们可以知道的是,数据关联部分的特征相似度计算,不仅要进行n:m的Kalman更新过程(为了求马氏距离),还要进行m:(nxk)的表观特征比对,这个过程很耗时。所以我们利用3-D integral image快速将空间区域分配,使得特征相似度计算过程的复杂度降至O(m+n)。
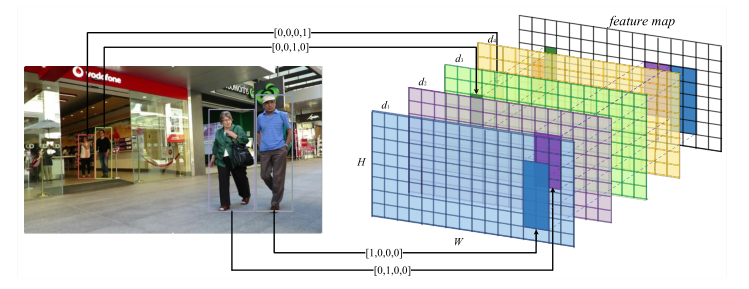
方法很巧妙,就是将每个观测框利用one-hot编码映射到特征图,这种方式比基于iou的要快很多:
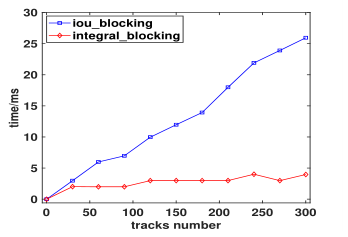
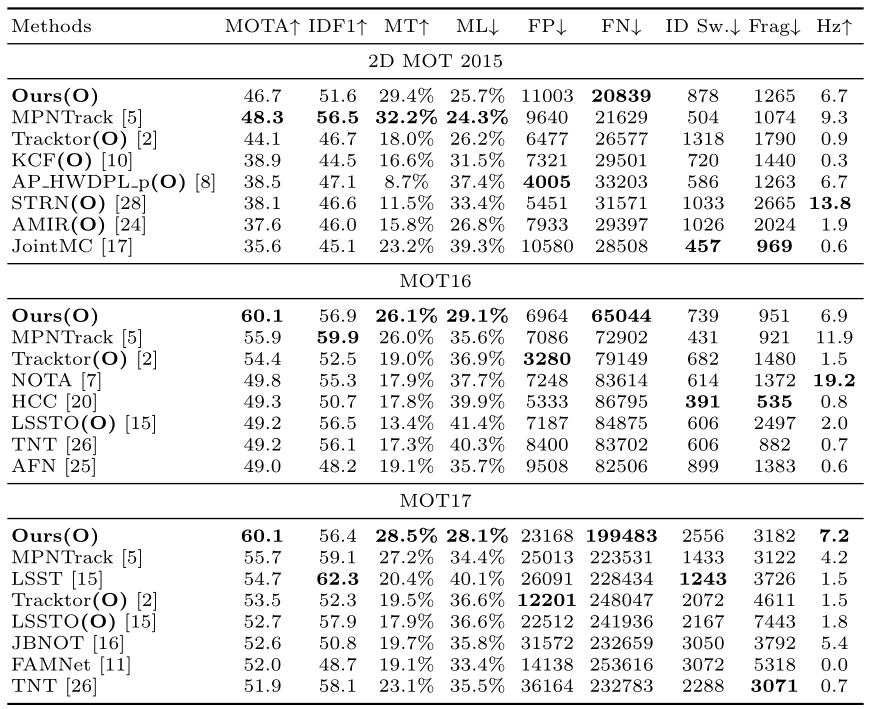
我后期又做了一些实验,效果比论文中的更好一些,MOT15~17: 48.1、60.4、60.1 MOTA(public)
7.Tracking Objects as Points(CenterTrack)
作者:Xingyi Zhou(CenterNet的作者), Vladlen Koltun, and Philipp Krähenbühl
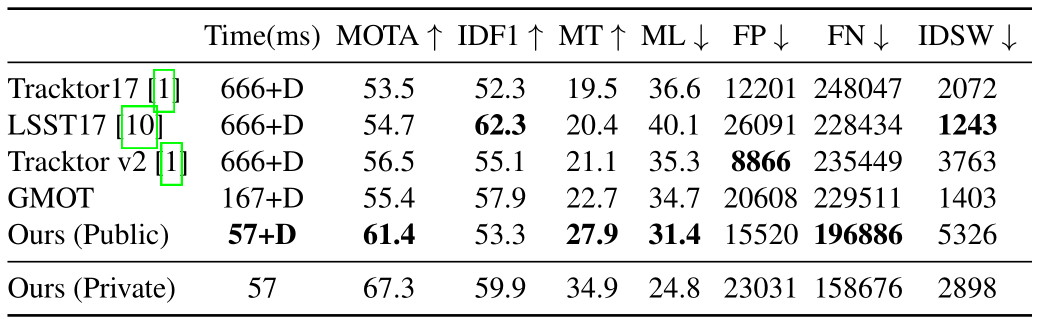
备注信息:同时实现了2D/3D多目标跟踪,包含人和车辆,MOT17:61.4(public)、67.3(private) MOTA, 22FPS!!!
KITTI:89.4MOTA
CenterTrack是CenterNet作者基于Tracktor++这类跟踪机制,通过将Faster RCNN换成CenterNet实现的一种多目标跟踪框架,因此跟踪框也就变成了跟踪中心点。
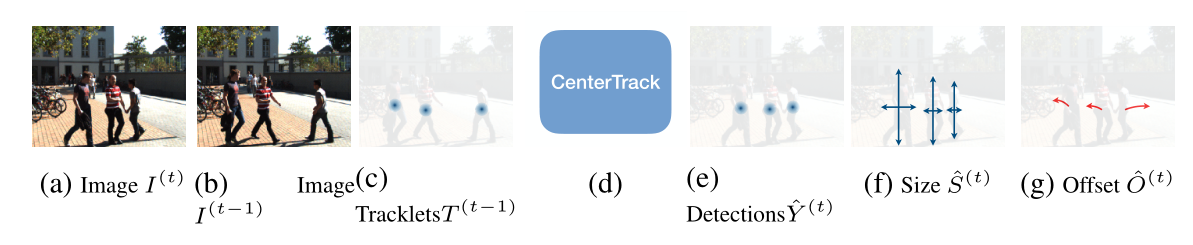
通过上图我们可以大致分析出算法框架,除了对相邻两帧利用CenterNet进行检测之外,还利用了上文中提到的D&T框架的策略,预测同时存在于两帧中目标的相对位移,由此进行跟踪预测。对于提供的观测框,作者通过将这些观测框的中心点映射到一张单通道的heatmap上,然后利用高斯模糊的方式将点的附近区域也考虑进去。
因此CenterTrack相对于CenterNet的不同之处在于,输入维度增加了(两幅3维图像和一张观测位置heatmap),输出变成了两张图像的目标中心位置、大小和相对偏移。
对于测试环节的数据关联部分,作者直接通过中心点的距离来判断是否匹配,是一种贪婪的方式,并非匈牙利算法那种全局的数据关联优化。在训练过程中,作者并非只用相邻帧进行训练,允许跨3帧。
CenterTrack在MOT、KITTI和nuScenes等数据集上的2D/3D多行人/车辆跟踪任务上均取得了SOTA的成绩。

参考文献
[1] Feichtenhofer C, Pinz A, Zisserman A. Detect to track and track to detect[C]. in: Proceedings of the IEEE International Conference on Computer Vision. 2017. 3038-3046.
[2] Chen L, Ai H, Zhuang Z, et al. Real-time multiple people tracking with deeply learned candidate selection and person re-identification[C]. in: 2018 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2018. 1-6.
[3] Bergmann P, Meinhardt T, Leal-Taixe L. Tracking without bells and whistles[C]. in: Proceedings of the IEEE International Conference on Computer Vision. 2019. 941-951.
[4] Multiple Object Tracking by Flowing and Fusing
[5] Towards Real-Time Multi-Object Tracking
[6] Refinements in Motion and Appearance for Online Multi-Object Tracking
[7] Tracking Objects as Points

