前言
昨天看到一篇商汤的刷榜文《1st Place Solutions for OpenImage2019 - Object Detection and Instance Segmentation》,里面的每个技巧我们都见过,还有很多依靠大量计算资源的参数搜索和模型集成。不过其中关于回归和分类的冲突勾起了我的回忆,去年整理了一些相关的文章。我准备在简要介绍这片文章的同时,谈谈目标检测(two-stage和one-stage)中特征的冲突和不对齐问题,以及现有的改进方案。
1 Two-stage目标检测中的特征/任务冲突问题
1.1 Two-stage目标检测的流程与原理
说起两阶段目标检测算法,大家耳熟能详的就是Faster RCNN系列了,目前的大多数两阶段算法也都是在其基础上进行的改进。不过现在新出的很多“N-阶段”的算法把大家搞混了。所以我这里申明一下两阶段的意义,我们通常说的两阶段是以Faster RCNN算法为基准的,第一阶段是特征提取和候选框提取,主要是RPN网络,第二阶段是对候选框进行进一步筛选、精修和细分类,主要是ROI Pooling/Align等网络。
在我的上一篇博文中提到过两阶段目标检测的关于平移不变性和相等性的矛盾问题,这里我们详细探讨一下。两阶段目标检测中,第一阶段做的事前/背景分类和候选框回归,第二阶段做的是候选框精修回归和细分类。正如之前所讨论的,分类任务希望无论目标的位置和形状怎么变化,什么类别的目标就是什么类别,即需要保证平移和尺度的不变性。而回归任务,我在上一篇博文中提到了,对于物体位置的回归很大程度可能依赖padding信息,当然这不是这次的讨论重点,回归需要保证目标的位置和形状变化反映在特征上,进而回归得到位置,即平移和尺度的相等性。这一问题在行人检索中更加严重,因为行人检索问题中的识别任务要求同类目标的不同身份要区分开,这一点就与目标检测中的分类任务相违背,因为检测中的分类不论什么身份,只要属于同一类别即可。
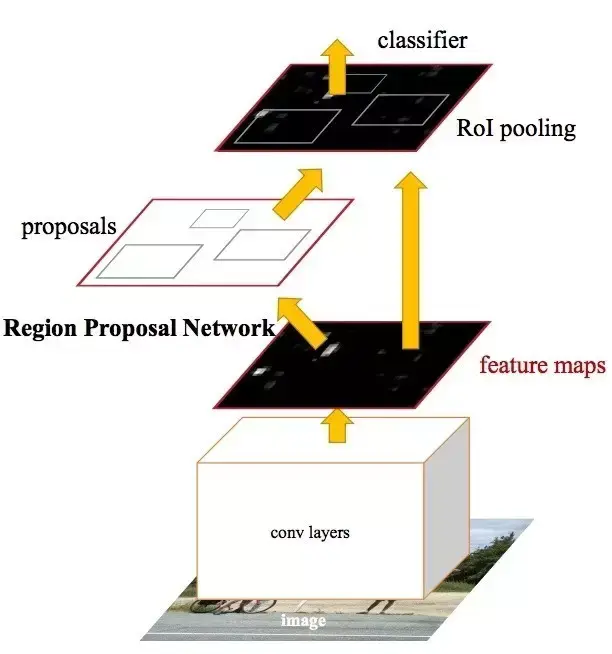
1.2 现有的相关解决方案
在正式介绍相关改进策略之前,我们先提提Cascade RCNN算法[3],其原理如下:
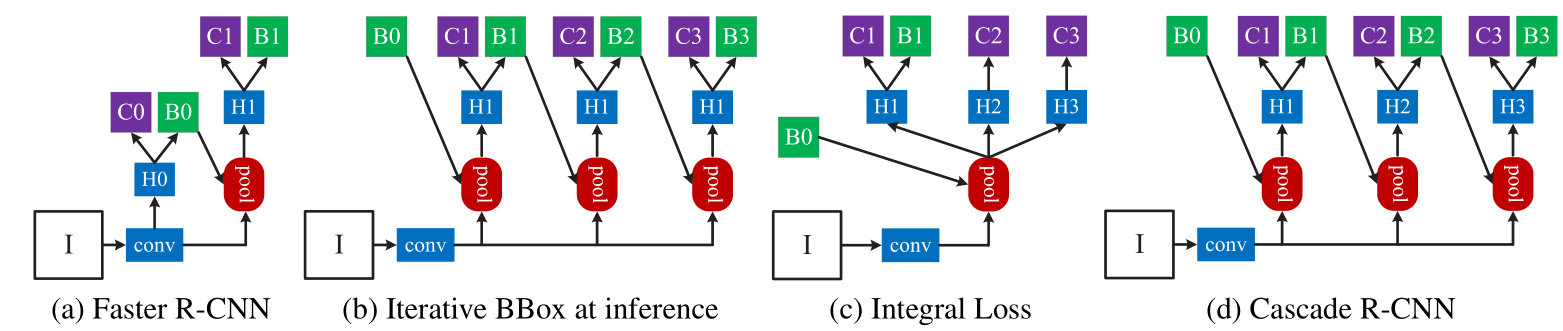
要注意的是Iterative bbox方式和Cascade RCNN方式的形式虽然一样,但是不同之处在于前者仅仅是用于测试阶段,可以观察到都是head network都是一样的,而后者各个head network都是训练来的。从形式来看,很明显就是将最后的分类和回归分支级联做了3次。这样做的依据就是:
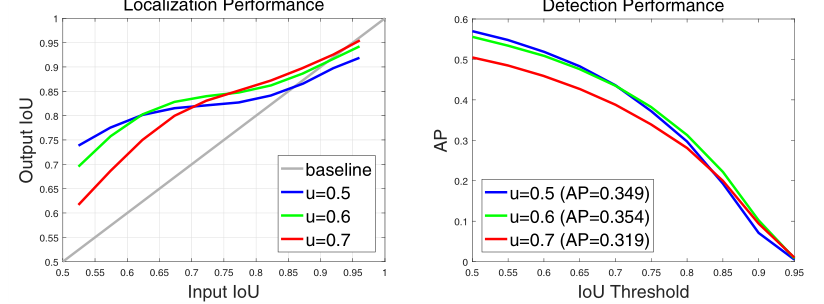
第一幅图中横坐标是回归前候选框与gt的iou,纵坐标是回归后的iou,可以看到不同的候选框质量对于回归效果也有影响。第二幅图中基于不同iou阈值训练得到的网络对于AP也有影响。再考虑到训练集和测试集内样本分布的不同,作者采用分而治之的策略,分别用{0.5,0.6,0.7}三种IOU阈值级联训练。这里提到了各阶段的具体训练方式:
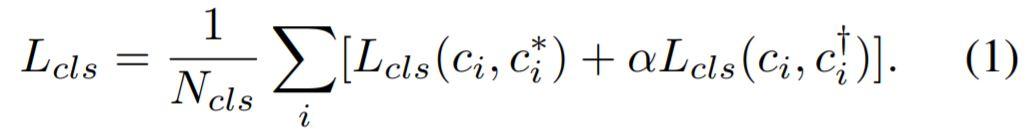
分类和回归都是一个模式,不仅用gt的标签,还用到了上一阶段的结果作为标签,来保证结果的稳定性。最后我们来看看各种方案的对比实验结果:
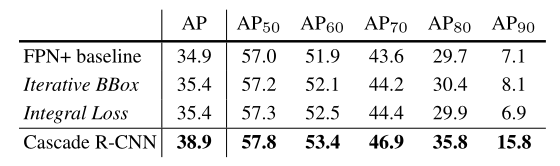
可以看到的是iterative bbox(以不同iou阈值做多次nms)和integral loss(以不同iou阈值并联多个回归和分类过程)都能提升一点点AP,但是Cascade RCNN(以不同iou阈值级联多个回归和分类过程)效果提升最大。
好了,我们回归正题,Cascade RCNN从样本质量分布mismatch和iou等角度进行了级联的refine操作。那么在IOU-Net[4]则是显式地说明了分类的分数不适合用于NMS的过滤,因为分类置信度高的样本不一定真的好。因此作者增加了一个样本与gt的iou预测阶段,以此作为NMS的排序依据。这里实际上就说明了分类和回归的冲突问题。
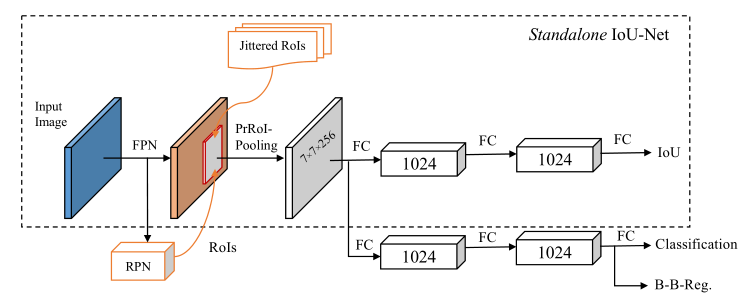
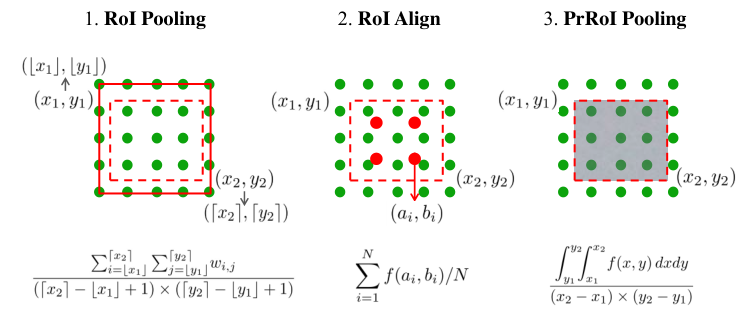
至于为了提高预测精度的PrROI-pooling,我就不仔细分析其原理了,不是这里的讨论重点:
那么真正意义上把分类和回归问题放在明面上的我觉得是Double-Head RCNN[2],来自于18年COCO检测冠军旷视团队。
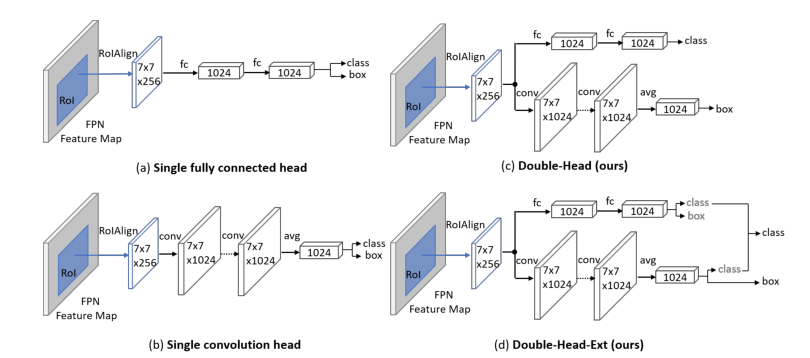
我们可以看到,不同于传统的将回归和分类放在最后阶段,利用两个全连接分支来预测,Double-Head直接从ROI Align之后就将两个人任务分开了,尽可能减少二者共享的特征部分。而Double-Head-Ext方案则是让两个分支都能预测类别和位置。

可以看到,四种方案下平衡两个分支损失函数权重后,后两种的效果明显更好。最后我们来看看CVPR2019的Guided Anchoring算法。
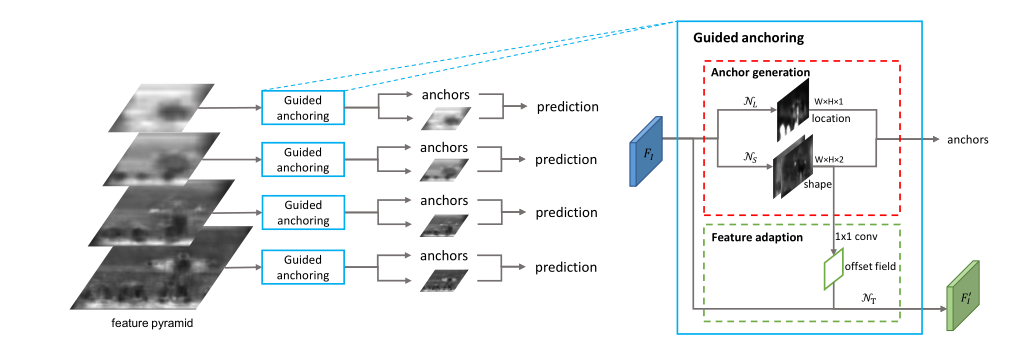
这个算法解决的是anchor的设计问题,而anchor的设计需要解决形状对齐和特征一致性的问题。其中形状对齐指的是以往anchor的尺寸和长宽比都是预设的固定几个,首先这也是超参数,其次无法适应多样的样本形状,因此该算法以特征图每个点作为中心,先预测anchor的长宽,再用于预测。而特征一致性问题则是一个很巧妙的问题,原因在于,同一层的特征图上每个点的感受野一致,但是预测到的anchor尺寸却不同,那么基于不同大小的anchor来做的分类任务却基于相同的特征感受野,这显然是存在问题的。所以作者基于预测得到的anchor长宽,利用deform-conv为每个anchor分配了新的特征区域,其中deform-conv中的offset直接采用预测得到的anchor长宽。
2 One-stage目标检测中的特征不对齐问题
2.1 One-stage目标检测中的问题
One-stage目标检测算法,以YOLO系列、SSD系列、RetinaNet等为经典,下面是YOLOv3的网络流程:
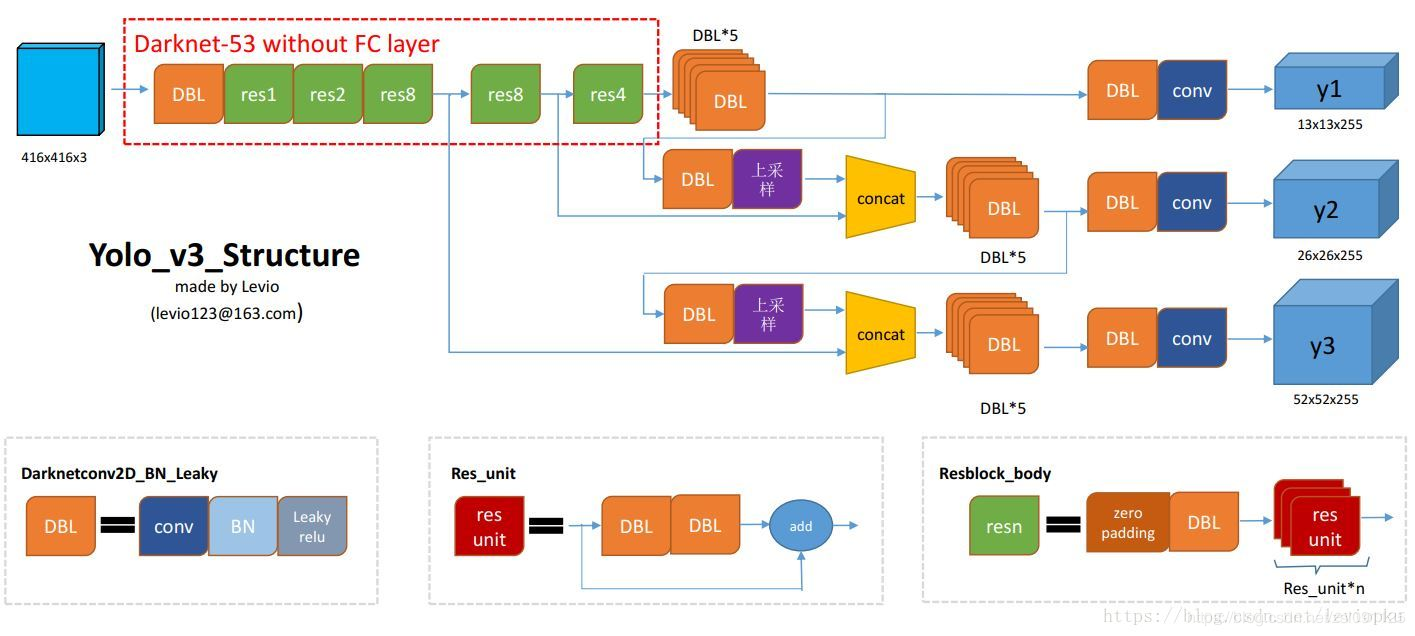
我们可以看到的是单阶段的目标检测算法相当于取消了RPN阶段,所以两阶段目标检测中遇到的问题(分类与回归特征冲突,anchor与特征不对齐),在单阶段目标检测中只会更加严重。不过单阶段目标检测的目标就是提升速度,所以我目前并没有看到对第一个问题的解决方案,而去年对于anchor与特征不对齐的问题有好多解决策略。原因在于两阶段目标检测中ROI Pooling本身有一个利用候选框裁剪特征区域的过程,缓解了这一问题,而单阶段目标检测却没有这一过程。
2.2 “1.5-stage”解决策略
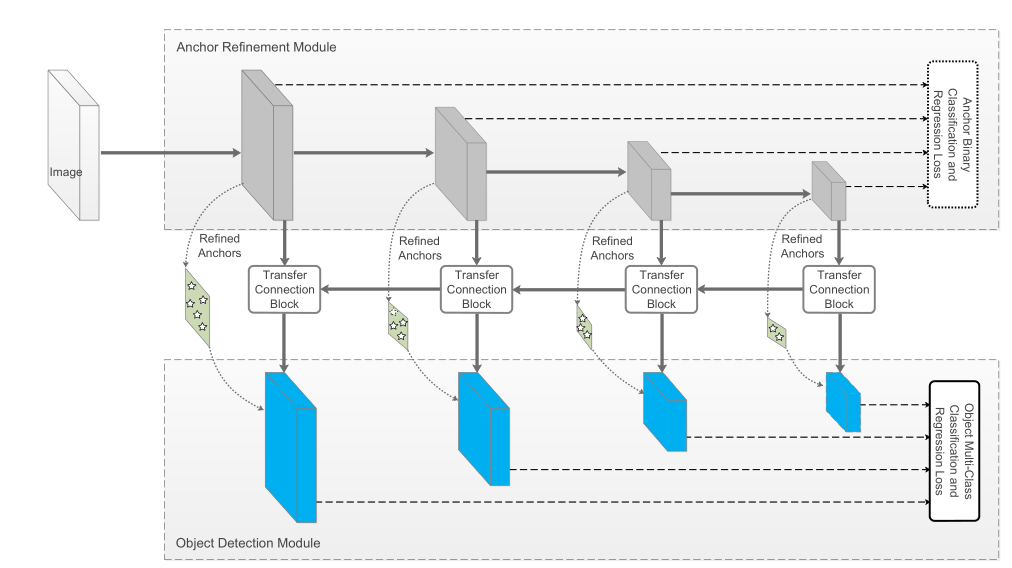
CVPR2018有一篇RefineDet算法[9],这个算法是针对SSD算法的改进,融合了单阶段和两阶段的设计思路,但又不是我们之前所说的RPN+ROIPooling这类框架,所以就叫它“1.5stage”检测框架吧。RefineDet有两个模块,其中上面是ARM,用于调整anchors的位置和大小,下面是ODM,用于目标检测。这个跟Guided Anchoring的设计思路很像,不过比较简陋。除此之外,RefineDet还采用了级联预测的模式,利用中间的TCB模块,其通过Deconv和特征Concat反向级联,类似于FPN的模式。
同样地,相同的团队在AAAI2019的一篇人脸检测算法SRN[6]也用了RefineDet的框架:
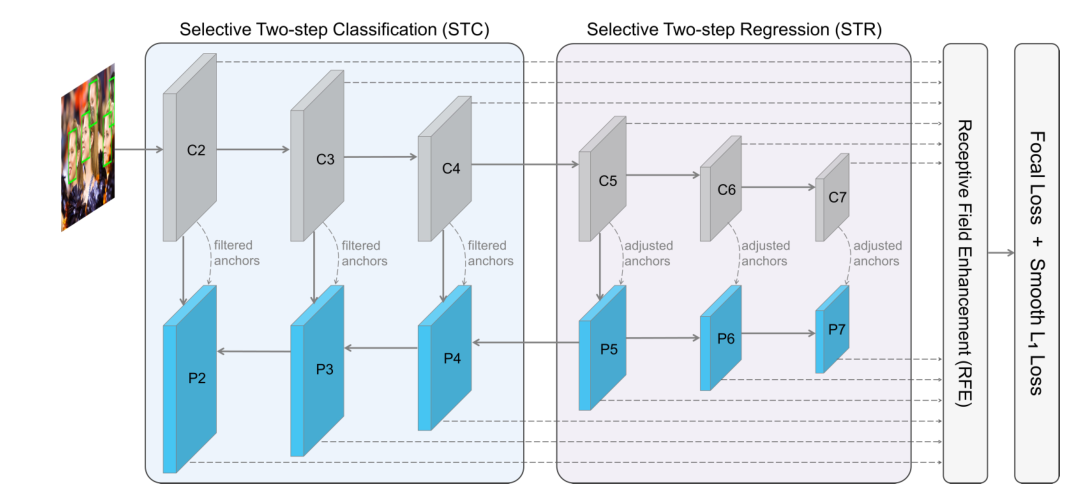
可以看到整体框架很像,但是却有所不同,SRN框架包含有STC+STR+RFE三个模块。其中STC模块作用于浅层网络,用于过滤掉大部分的负样本,STR作用于高层特征,用于粗略调整anchor,类似于RefineDet。而RFE则是在接受各个尺度特征的同时,利用非正方形的卷积核对感受野进行增强(考虑到人脸不一定是正的)。
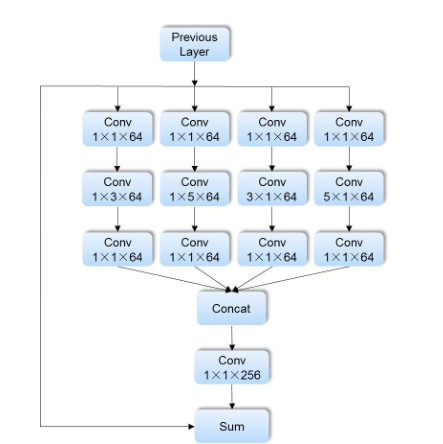
在ICCV2019中有一篇比较特别的检测算法Reppoints[7],其出来的时机正好是anchor-free算法大火的时候,其框架比较特别,可以看作是DCN+Refine操作的集成,有人也称其为DCNv3:
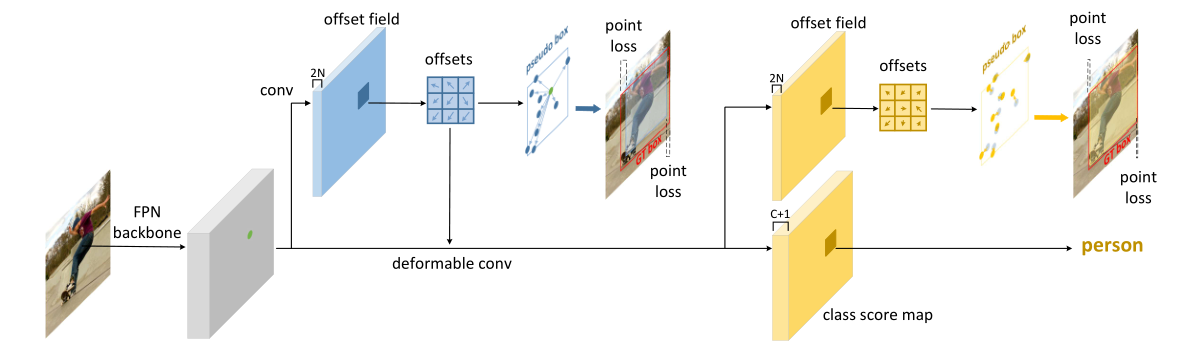
这个框架的特别之处在于没有预测框,没有预测中心或者角点,而是预测的目标边缘的九个点。不过我觉得这几个特征点更像是一种解释,而不是出发点。其原理是以特征图上每个点为中心,预测包含该位置的目标的九个边缘点。其方式是通过卷积的方式预测各个点的相对位置(x,y)偏移,以此作为Deform Conv的偏移量对原特征图进行卷积,由此使得特征与目标区域更加重合,从而进行第二阶段的预测。可以发现,Reppoints很像anchor free版的Guided Anchoring,而之前提到的RefineDet和SRN虽然提到了anchor预更新,但是特征并没有校正。
WACV2020的一片P&A算法[5]算是对上面的不足做了完善,但是我感觉像是把Guided Anchoring中的Feature Adaption直接搬过来了,为什么这么说呢。因为P&A也是先预测anchor偏移和前景背景分类,然后以此作为deform conv的offsets对特征重提取,再进行目标位置回归和细分类。
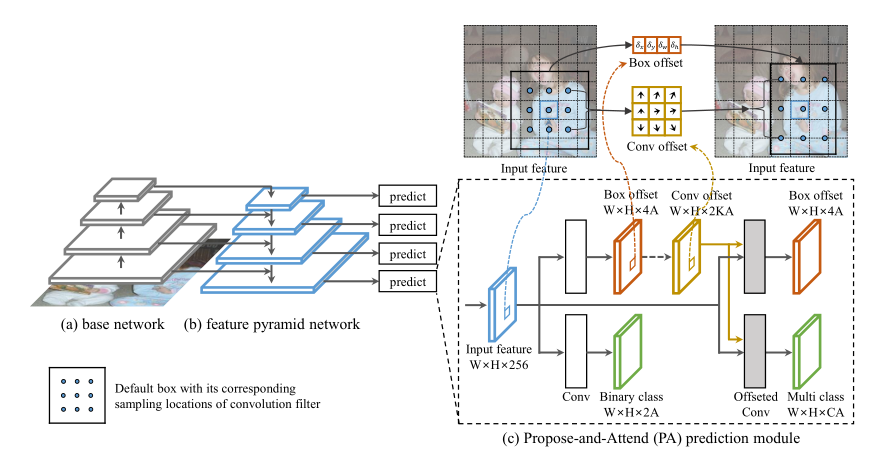
同时间出来的AlignDet[8]则是提出了ROIConv:
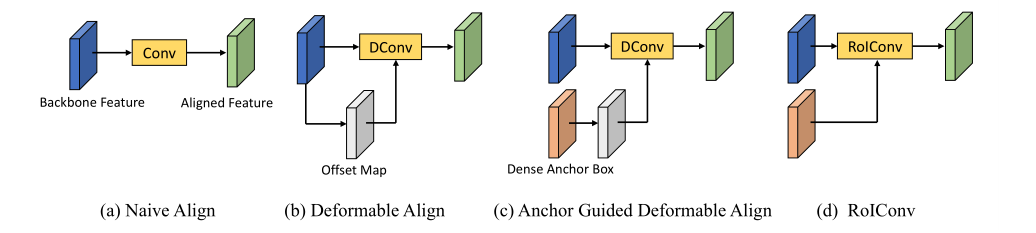
上图中(a)指的就是RefineDet类的对齐,(b)就是Reppoints一类的对齐,(c)就是Guided Anchoring类的对齐,(d)就是AlignDet类的对齐。AlignDet把基于anchor偏移量的特征对齐称作ROIConv,还分析了具体的偏移校正过程:
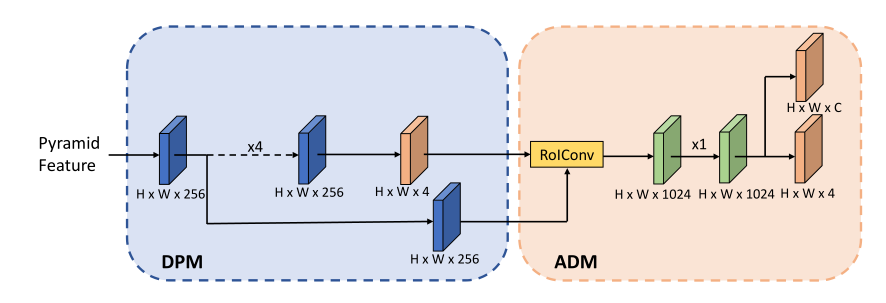
可以看到有两次预测过程,作者采用了Cascade的 方式,两次的IOU阈值不同。其实仔细看的话P&A和AlignDet的结构几乎一模一样,看评审怎么看吧,估计也是考虑到这方面因素给挂了。
3 《1st Place Solutions for OpenImage2019 - Object Detection and Instance Segmentation》介绍
现在我们来看看商汤在OpenImage2019上的文章,可以当作技术报告来看。我们直接按照论文提到的创新点或者工作来一一说明。
Decoupling Head
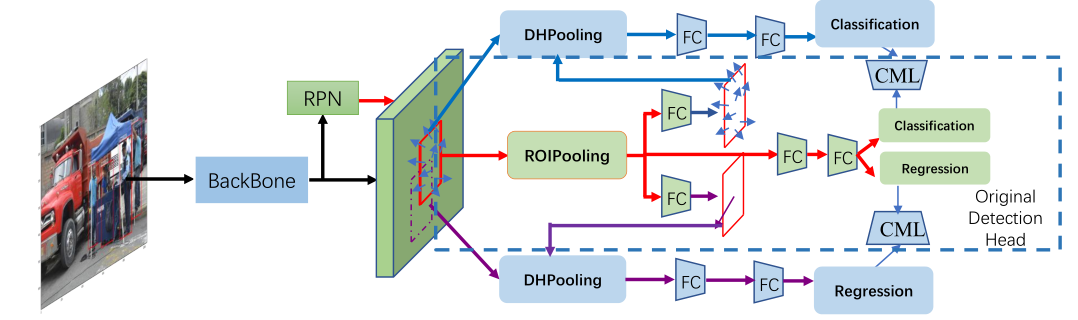
作者出发点是目标检测框架中分类的回归任务对于特征的要求不同,而这一点在我上面提到的Double Head RCNN已经提过了。Decoupling Head则是考虑到我们前文提到的anchor和特征不对齐问题,利用传统的ROI Pooling主干预测anchor的粗略位置,然后用deform conv的方式校正分类分支。再在主干上保留原始的回归和分类任务。总而言之可以将其概括为:Double Head RCNN + AlignDet + Faster RCNN
Adj-NMS
这部分作者的描述方案很“有意思”,作者考虑到NMS和soft-NMS的不足,先利用0.5的IOU阈值做了一次NMS,将靠得比较近的候选框过滤掉了,然后再用基于高斯核的soft-NMS做二次过滤。

我们可以根据这个公式来看看,假设分类置信度阈值为0.5,候选框分类置信度为1,那么Soft-NMS阶段要想留下,IOU必须小于0.59,而第一次的NMS已经将IOU>0.5的候选框过滤掉了,所以这个理论上可行。因此我们可以认为作者几乎不怎么考虑特别密集拥挤的场景了。

其效果也有0.174个点的提升。其实如果注意的话,有点像前文介绍Cascade RCNN是所提到了Iterative bbox策略,即做多次NMS。SoftNMS只能通过重新打分捞回原本得分比较低的样本,但是NMS已经将大部分的候选框给过滤掉了,所以我很好奇这是怎么生效的。
Model Ensemble
很多大型比赛的固定策略“Ensemble”,已经不奇怪了。naive ensemble的策略是借鉴的2018年的OpenImage第二名,给定bounding boxes(P),以及topk个与之IOU较高的候选框,依据验证集的分数来分配各个模型在集成时的权重,这里还分各个目标类别,然后进行加权:
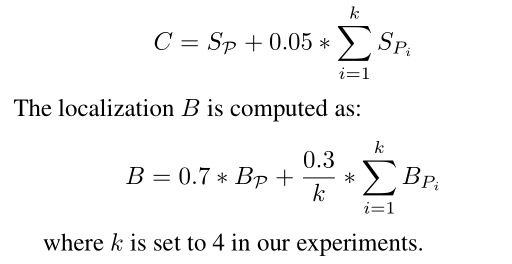
这里作者训练了28个目标检测网络….,利用二叉树的方式进行模型空间搜索。
Data Re-sampling
确保500个类别的目标中各个类别被选取的概率相等。
Decoupling Backbone
对于第25~28个模型,采取Decouple Head的策略,其中回归分支的权重较小。
Elaborate Augmentation
随机选择一个类别,利用旋转放缩裁剪等方式进行数据增强,这样可以使得一幅图中的类别数变少,缓解数据不平衡问题。
Expert Model
利用专门的网络训练专门的子类别数据集,这里面考虑了正负样本均衡的问题,容易混淆(标注标准不同,表观相似)的样本。
AnchorSelecting
跟YOLO系列一样,利用k-means方法得到18组anchors(6种长宽比,3种尺寸)。
Cascade RCNN
设置了0.5,0.5,0.6,0.7四个阶段的级联检测,这我就搞不懂Adj-NMS干嘛用的了。
Weakly Supervised Training
由于OpenImage数据集中各类别的“长尾分布”很明显,严重不均衡,所以作者增加了一些图像级的标注,结合有监督和WSDDN算法中的弱监督算法联合训练。
Relationships Between Categories
作者通过分析数据集中部分类别目标之间的联系,比如person和guitar等等,类似于条件概率,来修正分类置信度,比如一个有person在旁边的guitar要比没有person的guitar置信度要高。
Data Understanding
作者发现OpenImage数据集中对于特定类别的目标标注有歧义,比如火炬和手电筒,剑和匕首等,所以作者将有歧义的类别细分成了上面说的多类。同时作者也发现有些目标,比如葡萄缺乏个体检测框等,作者就利用葡萄串的实例标注,扩展了很多葡萄框。
最后的分割部分我就不细讲了,就是基于HRNet和Ensemble的方式进行的实验。
4 说在后面的话
实际上目标检测任务与多目标跟踪(MOT)也有很多联系,比如MOT数据集中的MOT17Det,又比如新出的基于类检测框架的Tracktor++算法,检测跟踪结合的框架JDE算法等。多目标跟踪领域绝不是一个局限于数据关联的独立领域,应该是个多领域融合的方向。之前基于COCO的预训练模型在MOT17数据集上试了下,在MOT17Det上居然还有0.88AP,然后我基于这个又复现了下Tracktor++,居然也达到了58+MOTA,后面有机会我放github吧。对了,还有个Crowdhuman人体检测的算法分享。
唉,公司又推迟入职时间了,先申请看能不能提前入职吧,不然只能在家减肥看论文做实验了…
参考资料
[1] 1st Place Solutions for OpenImage2019 - Object Detection and Instance Segmentation.
[2] Rethinking Classification and Localization for Object Detection
[3] Cascade r-cnn_ Delving into high quality object detection
[4] Acquisition of Localization Confidence for Accurate Object Detection
[5] Propose-and-Attend Single Shot Detector
[6] Selective Refinement Network for Face Detection
[7] Reppoints_ Point set representation for object detection
[8] Revisiting feature alignment for one-stage object detection
[9] Single-Shot Refinement Neural Network for Object Detection

