前言
由于最近忙着整理毕设以及小论文发表,所以有些内容我暂时不能分享出来,先从多目标跟踪领域的基础知识开始分享,后续也会陆续结合代码讲解。如果有机会,还可以分享我在MOTChallenge上刷到sota的经验。这次先结合一篇综述和我的理解进行一个背景介绍。
1. 多目标跟踪简介
多目标跟踪可认为是多变量估计问题,即给定一个图像序列,$s_t^i$表示第 t 帧第 i 个目标的状态,${S_t} = \left( {s_t^1,s_t^2,...,s_t^{{M_t}}} \right)$表示第 t 帧所有目标的状态序列,$s_{{i_s}:{i_c}}^i = \left( {s_{{i_s}}^i,...,s_{{i_e}}^i} \right)$ 表示第 i 个目标的状态序列,其中${i_s}$和${i_e}$分别表示目标 i 出现的第一帧和最后一帧,${S_{1:t}} = \left( {{S_1},{S_2},...,{S_t}} \right)$表示所有目标从第一帧到第t帧的状态序列。这里的状态可以理解为目标对应图像中哪个位置,或者是否存在于此图像,这个是算法所求得的所有信息。
在多目标跟踪领域最常见的就是tracking-by-detection算法,通过匹配得到对应的观测目标${O_t} = \left( {o_t^1,o_t^2,...,o_t^{{M_t}}} \right)$ ,${O_{1:t}} = \left( {{O_1},{O_2},...,{O_t}} \right)$ 表示所有目标从第一帧到第t帧的观测目标序列,这里的目标都是我们观测到的位置。
那么多目标跟踪的目的就是找到所有目标的最佳状态序列,而在所有观测目标的状态序列上的条件分布上,可以通过最大化后验概率(MAP)得到。这里可以区分一下最大似然概率(MLE)和最大后验概率(MAP):
最大似然概率
要了解最大似然概率,首先要区分似然(likelihood)和概率(probability),这里提出函数$P\left( {x|\theta } \right)$。其中$x$表示某一数据,$\theta $表示模型参数。那么当$x$为变量,$\theta $为常量时,该函数为概率函数,表示在该模型下,出现不同$x$的概率;反之则为似然函数,表示对于不同的模型参数,出现该$x$的概率,所以概率函数更偏向于结果,似然函数更偏向于结构化。
了解了似然函数,顾名思义,最大化似然函数就是怎样设置模型参数能让一个预期的结果以最大概率出现。下面给出一个简单例子:
抛掷一枚硬币多次,假设硬币正面朝上的概率为$\theta $,那么出现事件${x_0}$=“反正正正正反正正正反”的似然函数就是:
$$ f\left( {{x_0},\theta } \right) = \left( {1 - \theta } \right) \times {\theta ^4} \times \left( {1 - \theta } \right) \times {\theta ^3} \times \left( {1 - \theta } \right) = {\theta ^7} \times {\left( {1 - \theta } \right)^3} $$
可以发现,当 $\theta $=0.7时该似然函数最大,也就是说当 $\theta $=0.7时,事件${x_0}$ 的出现概率最大,为0.22%。最大后验概率
最大似然函数是最大化似然函数,那么最大化后验概率则是在此基础上考虑了模型参数 $\theta $,其认为该参数也有概率分布,即先验概率。所以最大化后验概率是在最大化下面的函数:
P\left( {\theta |{x_0}} \right) = \frac{{P\left( {{x_0}|\theta } \right)P\left( \theta \right)}}{{P\left( {{x_0}} \right)}} $$
那么现在问题就比较抽象了,还是举个栗子说明吧。假设我们先验的认为 $\theta $=0.5的概率较高,那么不妨先假设$\theta $的先验概率分布为均值为0.5,方差为0.1的高斯分布。即硬币正面朝上概率的先验分布如下: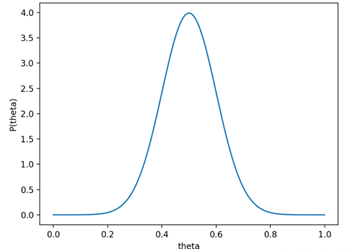
后验概率对应的分布为:
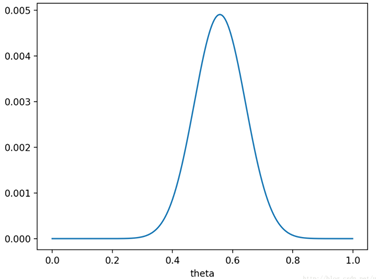
这里的分布与后验概率分布趋势一致,只是纵坐标绝对值不同而已,可以看到,当 $\theta $ =0.558时,后验概率最大,由此可见与最大似然概率的不同。
回到多目标跟踪问题上,最大化后验概率在这里的体现就是在观测目标已知的前提下,选择最合理的状态序列分布,使得该观测目标序列出现的概率最大:
$$ {\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}} \over S} _{1\;:\;t}} = \mathop {argmax}\limits_{{S_{1\;:\;t}}} P\left( {{S_{1\;:\;t}}|{O_{1\;:\;t}}} \right) $$
2分类
多目标跟踪问题由于比较复杂,所以基于不同假设前提的挑战赛有很多,由此作为多目标跟踪的分类依据。
2.1初始化方法
不同于单目标跟踪,多目标跟踪问题中并不是所有目标都会在第一帧出现,也并不是所有目标都会出现在每一帧。那么如何告知算法出现了新目标变成了一个问题,即不同的初始化方法。常见的初始化方法分为两大类,一个是Detection-Based-Tracking(DBT),一个是Detection-Free-Tracking(DFT)。
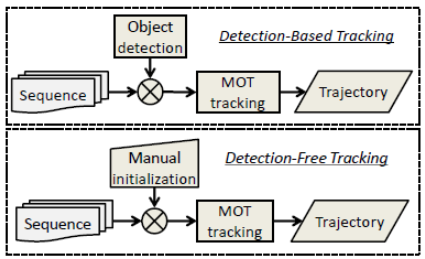
DBT
可以看到,DBT的方式就是典型的tracking-by-detection模式,即先检测目标,然后将目标关联进入跟踪轨迹中。那么就存在两个问题,第一,该跟踪方式非常依赖目标检测器的性能,第二,目标检测的实质是分类和回归,即该跟踪方式只能针对特定的目标类型,如:行人、车辆、动物。
DFT
DFT是单目标跟踪领域的常用初始化方法,即每当新目标出现时,人为告诉算法新目标的位置,这样做的好处是target free,坏处就是过程比较麻烦,存在过多的交互,所以DBT相对来说更受欢迎。
2.2处理模式
同样地,MOT也存在着不同的处理模式,Online和Offline两大类,其主要区别在于是否用到了后面帧的信息。
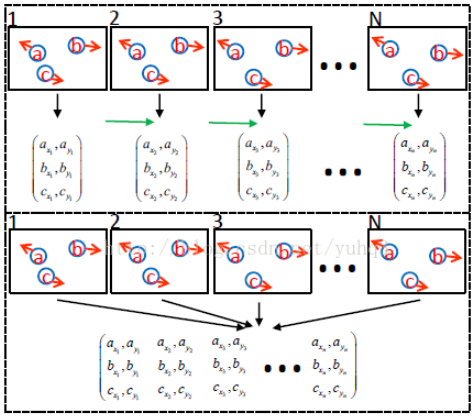
Online Tracking
Online Tracking是对视频帧逐帧进行处理,当前帧的跟踪仅利用过去的信息。
Offline Tracking
不同于Online Tracking,Offline Tracking会利用前后视频帧的信息对当前帧进行目标跟踪,这种方式只适用于视频,如果应用于摄像头,则会有滞后效应,通常采用时间窗方式进行处理,以节省内存和加速。
3外观模型
3.1视觉表达
全局颜色特征
全局颜色特征除了灰度(即RGB2GRAY)之外,比较有名的就是单目标跟踪领域中的CN2特征了,该颜色特征将颜色空间划分为了黑、蓝、棕、灰、绿、橙、粉、紫、红、白和黄共11种,然后将其投影至10维子空间的标准正交基上。具体过程可见我之前关于KCF的一片博客。
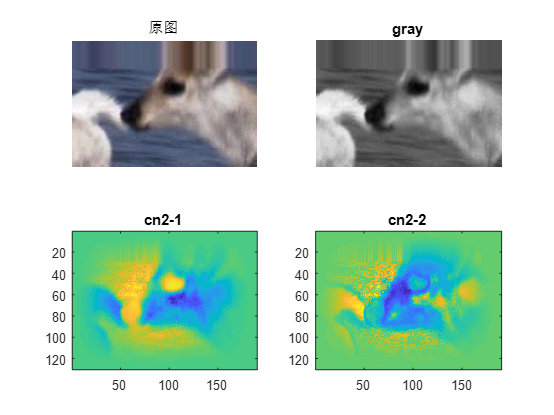
局部特征
局部特征比较典型的就是光流法,其中比较典型的有KLT(Kanade-Lucas-Tomasi Tracking)算法,这个算法在CVPR94中经由来Jianbo Shi和Carlo Tomasi两人在《Good Features to Track》一文中提出shi-tomasi角点而改进,光流法的好处就是方便提取运动轨迹信息。其中在多目标跟踪领域利用光流特征比较出名的是NOMT算法:
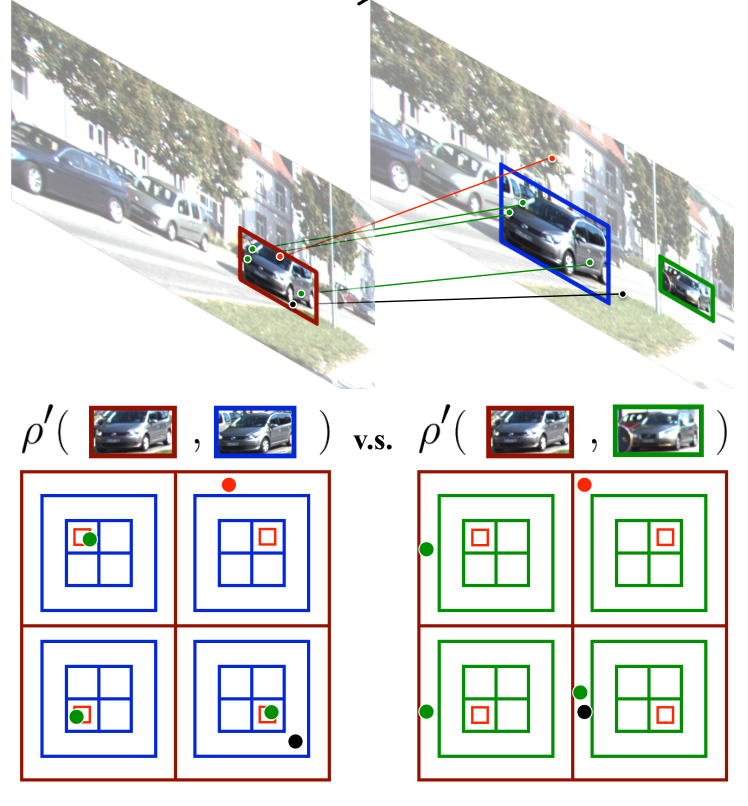
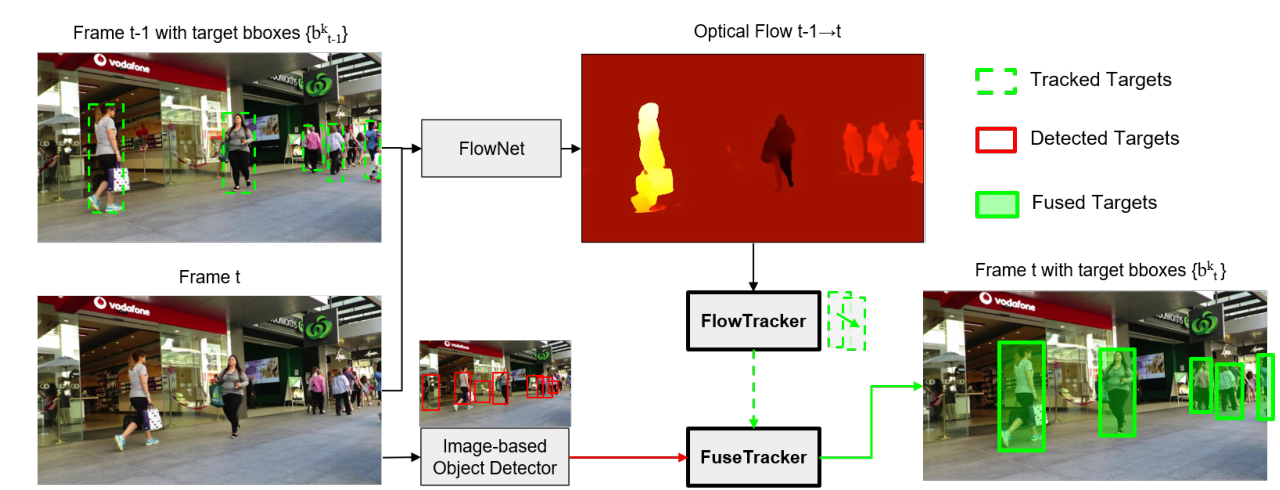
不过近几年深度学习领域发展迅速,基于深度光流框架(FlowNet系列等)的也有,比如最近刚出的《Multiple Object Tracking by Flowing and Fusing》,就是很粗暴地结合光流 和检测框架。
区域特征
和局部特征不同的是,区域特征是针对选定的区域进行特征提取的,以区域间的关系不同可分为三类:
- Zero-Order:这一层面一般指的是颜色特征,常用的有颜色直方图,亦或是类似于全图特征;
- First-Order:这一层面的特征则是用到了梯度信息,最常见的就是HOG特征,还有不常见的水平集特征;
- Up-to-Second-Order:这一层面用到了二阶梯度,一般采用区域协方差矩阵。
深度特征
现在深度学习领域中关于backbone框架的各种变种层出不穷,比如ResNet,VGGNet等。特征的选择有很多,我们可以根据速度、精度、鲁棒性三个方向进行不同的选择,当然也能针对特定的场景进行选择。比如颜色直方图经常使用,然而其忽略了目标区域的空间分布。局部特征是高效的,但是对遮挡和平面外旋转敏感,基于梯度的特征例如HOG可以描述目标的形状并且对光照有适应性,但它不能很好地处理遮挡和变形。区域协方差矩阵相对来说比较鲁棒,因为它们使用了较多的信息,但同时带来了较高的计算复杂度。
目标跟踪领域的Martin大神在其之前的论文UPDT中对比分析了深度特征和浅层特征:
深度特征:主要是CNN的高层激活,典型VGGNet的layer 5。优点是包含高层语义,对旋转和变形等外观变化具有不变性,何时何地都能找到目标,即鲁棒性很强;缺点是空间分辨率低,对平移和尺度都有不变性,无法精确定位目标,会造成目标漂移和跟踪失败,即准确性很差。
浅层特征:主要是手工特征如RGB raw-pixel, HOG, CN,和CNN的低层激活,典型VGGNet的Layer 1。优点是主要包含纹理和颜色信息,空间分辨率高,适合高精度定位目标,即准确性很强;缺点是不变性很差,目标稍微形变就不认识了,尤其是旋转,一转就傻,即鲁棒性很差。
不过近几年由于行人重识别Re-ID领域的迅速发展,深度特征逐渐从基于图像分类任务的backbone框架转变到了基于Re-ID的识别类任务,这样更容易得到端到端的特征训练框架。尤其是在DBT框架中检测质量参差不齐,而且遮挡严重,训练框架需要对前景目标具有一定的捕捉能力,一个精心设计的端到端训练框架尤为重要。

3.2统计测量
统计测量即相似性度量,这里我们分为单线索和多线索两种方法:
单线索
使用单线索进行外观建模时要么是将距离转换为相似性,要么直接计算相似性,比如说归一化互相关,这一点有点像相关滤波,即对两个相同大小的区域进行相关运算,亦或是利用巴氏距离计算两直方图的距离,并将其转化为相似性,或者加入高斯分布进行转化。
多线索
多线索,顾名思义就是结合不同的线索进行特征融合,有以下这些方法:
Boosting:从特征池中选择一部分特征进行基于boosting的算法,例如对于颜色直方图、HOG、协方差矩阵,分别采用Adaboost、RealBoost和 HybirdBoost来区分不同目标各自的轨迹;
Concatenation:直接进行特征拼接
Summation:对不同的特征得到的相似度加权求和;
Product:如果说不同特征间独立,则可以将相似度相乘;
Cascading:使用不同的方法级联计算,例如考虑不同粗细粒度。
4运动与假设模型
为了简化现实生活中的多目标跟踪,我们可以引入一些假设来人为简化求解过程,分别有运动模型、交互模型、社会力模型、排斥模型和遮挡模型。
4.1运动模型
运动模型捕捉目标的动态行为,它估计目标在未来帧中的潜在位置,从而减少搜索空间。在大多数情况下,假设目标在现实中是平缓运动的,那么在图像空间也是如此。对于行人的运动,大致可分为线性和非线性两种运动:
线性运动:线性运动模型是目前最主流的模型,即假设目标的运动属性平稳(速度,加速度,位置);
非线性运动:虽然线性运动模型比较常用,但由于存在它解决不了的问题,非线性运动模型随之诞生。它可以使tracklets间运动相似度计算得更加准确。
当然,对于存在相机运动的场景也需要考虑相机运动,不过这就涉及到了一些相机几何知识了,我以后再开专题讲解。
4.2交互模型
交互模型也称为相互运动模型,它捕捉目标对其他目标的影响。在拥挤场景中,目标会从其他的目标和物体中感受到“力”。例如,当一个行人在街上行走时,他会调整他的速度、方向和目的地,以避免与其他人碰撞。另一个例子是当一群人穿过街道时,他们每个人都跟着别人,同时引导其他人。
- 社会力模型也被称为群体模型。在这些模型中,每个目标都被认为依赖于其他目标和环境因素,这种信息可以缓解拥挤场景中跟踪性能的下降。在社会力模型中,目标会根据其他物体和环境的观察来确定它们自己的速度、加速度和目的地。更具体地说,在社会力模型中,目标行为可以由两方面建模而成:基于个体力和群体力。
- 人群运动模型。通常这类模型适用于目标密度非常高的超密集场景,这时目标都比较小,那些外观、个人运动模式线索就会受到极大干扰,所以人群运动模式就相对比较适合,类似于元胞自动机或者有限元分析。该类模式又分结构化模式和非结构化模式,结构化模式主要得到集体的空间结构而非结构化模式主要得到不同个体运动的模式。通常来说,运动模式由不同方法学习得到,甚至考虑场景结构,然后运动模式可作为先验知识辅助目标跟踪。
4.3遮挡模型
一种比较流行的方法是将全局目标(类似一个跟踪框,bounding box)分割成几个部分,然后对每个部分计算相似度,具体来说就是当发生遮挡时,被遮挡的那些部分的相似度权重降低,而提高没被遮挡部分的相似性权重。至于如何进行分割,有将目标均匀地切分成一个个格子的,也有以某种形态例如人来切分目标的,还有由DPM检测器得到的部分。利用重构误差判断某个部分是否被遮挡,外观模型只根据可见部分进行更新,对于两个轨迹的相似度可利用各部分相似度加权求得。
而缓冲模型则是在发生遮挡前记录目标状态并且将发生遮挡时的观测目标存入缓冲区中,当遮挡结束后,目标状态基于缓冲区的观测目标和之前记录的状态恢复出来。当发生遮挡时,保持最多15帧的trajectory,然后推断发生遮挡时潜在的轨迹。当目标重新出现时,重新进行跟踪并且ID也维持不变。当跟踪状态因为遮挡而产生歧义时观测模式就会启动,只要有足够的观测目标,就会产生假设来解释观测目标。以上就是”buffer-and-recover”策略。
5概率预测型模型
概率预测模型大多都是基于两部迭代的方式,假设目标的状态转移服从一阶马尔科夫模型:
$$ \begin{array}{l} Predict:P(\left. {{S_t}} \right|{O_{1\;:\;t - 1}}) = \int {P(\left. {{S_t}} \right|{S_{t - 1}})P(\left. {{S_{t - 1}}} \right|{O_{1\;:\;t - 1}})d{S_{t - 1}}} \\ Update:P(\left. {{S_t}} \right|{O_{1\;:\;t}}){\rm{ = }}\frac{{P(\left. {{O_t}} \right|{S_t})P(\left. {{S_t}} \right|{O_{1\;:\;t - 1}})}}{{\int {P(\left. {{O_t}} \right|{S_t})P(\left. {{S_t}} \right|{O_{1\;:\;t - 1}})d{S_t}} }} \end{array} $$
其中预测阶段是动态模型,更新阶段为观测模型。
常见的概率预测型算法大致可分为以下几类:
传统概率模型。以Kalman滤波器和粒子滤波为主,其中Kalman滤波器依旧在MOT领域活跃,比如我们熟知的Sort系列;
联合概率数据关联。 联合概率数据互联JPDA是数据关联算法之一,它的基本思想是对应于观测数据落入跟踪门相交区域的情况,这些观测数据可能来源于多个目标。JPDA的目的在于计算观测数据与每一个目标之间的关联概率,且认为所有的有效回波都可能源于每个特定目标,只是它们源于不同目标的概率不同。JPDA算法的优点在于它不需要任何关于目标和杂波的先验信息,是在杂波环境中对多目标进行跟踪的较好方法之一。然而当目标和量测数目增多时,JPDA算法的计算量将出现组合爆炸现象,从而造成计算复杂。算法分成联合事件生成和关联概率计算两部分。
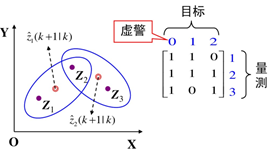
多假设跟踪。多假设跟踪MHT是数据关联另一种算法。它的基本思想是:与JPDA不同的是,MHT算法保留真实目标的所有假设,并让其继续传递,从后续的观测数据中来消除当前扫描周期的不确定性。在理想条件下,MHT是处理数据关联的最优算法,它能检测出目标的终结和新目标的生成。但是当杂波密度增大时,计算复杂度成指数增长,在实际应用中,要想实现目标与测量的配对也是比较困难的。在ICCV2015和CVPR2017都有相关的工作。
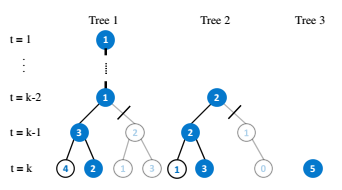
随机有限集。国内在这一块的研究都处于起步阶段,其优势在于无需考虑数据关联,不用先假设各种组合关系,不用担心出现“组合爆炸”情况,直接估测目标的个数和状态,这样就可以不需要目标检测的结果了,当然有了更好。即RFS直接将目标整体看做一个目标,因此多目标跟踪就变成了一个单目标跟踪问题,计算复杂度也是随着目标数量线性增长的,不过其理论比较挑战我的理论基础,有一本专门介绍概率型单/多目标跟踪的书籍《advances in statistical multisource-multitarget information fusion》,1000来页,1页一块钱,不过我最近发现了中文版《多源多目标统计信息融合》,才100多¥,数学hold住的可以看看。目前这块都需要基于一定的分布建模,典型的有PHD滤波和伯努利滤波。
6数据关联
大多数DBT框架都避免不了数据关联过程,数据关联分为以下几类:
- 偶图匹配。即在相邻两帧之间对跟踪轨迹和观测进行数据关联,常用的有IOU Matching(贪婪)、匈牙利算法/KM算法,也有少数人用MinCostFlow;
- 图论。这类算法大多用于离线跟踪的建模,比如MinCostFlow、最大流/最小割、超图等;
- 马尔可夫随机场和条件随机场等。
7深度学习模型
近两年,深度学习算法开始在MOT领域发展,一般分为这么几类:
- 以Re-ID为主的表观特征提取网络,如《Aggregate Tracklet Appearance Features for Multi-Object Tracking》;
- 基于单目标跟踪领域中成熟的Siam类框架构建的多目标跟踪框架,如《Multi-object tracking with multiple cues and switcher-aware classification》;
- 联合目标检测框架和单目标跟踪框架的多任务框架,如《Detect to track and track to detect》;
- 端到端的数据关联类算法,如《DeepMOT: A Differentiable Framework for Training Multiple Object Trackers》;
- 联合运动、表观和数据观联的集成框架,如《FAMNet: Joint learning of feature, affinity and multi-dimensional assignment for online multiple object tracking》;
- 基于LSTM类算法实现的运动估计、表观特征选择和融合等等算法。
8MOTChallenge评价体系
由于MOTChallenge是最主流的MOT数据集,所以我这里就以它为例进行介绍。其包含有MOT15~17三个数据集,其中MOT15提供了3D的坐标信息,包含5500帧训练集和5783帧测试集,提供了基于ACF检测器的观测结果。而MOT16和MOT17则包含5316帧训练集和5919帧测试集,其中MOT16仅提供了基于DPM检测器的观测,而MOT17则提供了SDP、FasterRcnn、DPM三种检测结果。
MOT提供的目标检测结果标注格式为: frame_id 、 target_id、 bb_left 、bb_top、 bb_width、bb_height 、confidence 、x 、y 、z 。即视频帧序号、目标编号(由于暂时未定,所以均为-1)、目标框左上角坐标和宽高、检测置信度(不一定是0~1)、三维坐标(2D数据集中默认为-1).
那么我们所需要提供的跟踪结果格式也是同上面一致的,不过需要我们填写对应的target_id和对应的目标框信息,而confidence,x,y,z均任意,保持默认即可。
相应地,官方所采用的跟踪groudtruth格式则为: frame_id、 target_id 、bb_left、bb_top、bb_width bb_height 、is_active、label_id、visibility_ratio 。其中is_active代表此目标是否考虑,label_id表示该目标所属类别,visibility_ratio表示目标的可视程度,目标类别分类如下:
| 类别 | 标签 | 类别 | 标签 |
|---|---|---|---|
| Pedestrian | 1 | Static Person | 7 |
| Person on vehicle | 2 | Distractor | 8 |
| Car | 3 | Occluder | 9 |
| Bicycle | 4 | Occluder on the ground | 10 |
| Motorbike | 5 | Occluder full | 11 |
| Non motorized vehicle | 6 | Reflection | 12 |
最后,数据集还提供了各个视频的视频信息seqinfo.ini,主要包括视频名称、视频集路径、帧率fps、视频长度、图像宽高、图像格式等。
根据MOT官方工具箱中的评价工具,可分析如下的评价规则:
Step1 数据清洗
对于跟踪结果进行简单的格式转换,这个主要是方便计算,意义不大,其中根据官方提供的跟踪groundtruth,只保留is_active = 1的目标(根据观察,只考虑了类别为1,即处于运动状态的无遮挡的行人)。另外将groudtruth中完全没有跟踪结果的目标清除,并保持groudtruth中的视频帧序号与视频帧数一一对应。为了统一跟踪结果和groudtruth的目标ID,首先建立目标的映射表,即将跟踪结果中离散的目标ID按照从1开始的数字ID替代。
Step2 数据匹配
将跟踪结果和groundtruth中同属一帧的目标取出来,并计算两两之间的IOU,并将其转换为cost矩阵(可理解为距离矩阵,假定Thresh=0.5)。利用cost矩阵,通过匈牙利算法(Hungarian)建立匹配矩阵,从而将跟踪结果中的目标和groundtruth中的目标一一对应起来。
Step3 数据分析
对视频每一帧进行分析,利用每一帧中的跟踪目标和groudtruth目标之间的匹配关系,可作出以下几个设定:
对于当前帧检测到但未匹配的目标轨迹记作falsepositive;
对于当前帧groudtruth中未匹配的目标轨迹记作missed;
对于groudtruth中的某一目标,如果与之匹配的跟踪目标ID前后不一致,则记作IDswitch;
对于已匹配的轨迹记作covered,总轨迹为gt。
其中,对于匹配和未匹配到的目标都有各自的评价依据,评价指标很多,这里就不细讲了,网上都有。
利用cost矩阵,通过匈牙利算法(Hungarian)建立匹配矩阵,从而将跟踪结果中的目标和groundtruth中的目标一一对应起来。
参考资源
[1] LUO W, XING J, MILAN A, et al. Multiple object tracking: A literature review[J]. arXiv preprint arXiv:1409.7618, 2014.

