前言
YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位的回归问题结合起来,从而做到了高效、灵活和泛化性能好。其backbone网络darknet也可以替换为很多其他的框架,所以在工程领域也十分受欢迎,下面我将依次介绍YOLO系列的详细发展过程,包括每个版本的原理、特点、缺点,最后还会交代相关的安装、训练与测试方法。
1.目标检测简介
YOLO(You Only Look Once)的作者非常萌,无论是写作风格、表情包还是Github风格,都表现出他是一个有趣的人。

好了,言归正传,众所众知,目标检测算法的核心在于:
候选区域/框/角点等的确定。神经网络/深度学习本质是分类,那么对于目标检测问题,我们需要将其转化为分类问题,因此许多研究者发现需要先确定候选位置,然后对候选位置进行分类判断。这里,候选区域的选取从最初的滑窗方式。

慢慢演变到以
Selective Search(过分割+分层聚类)为主的RCNN算法,为了更高效的生成候选区域,我们又利用卷积和池化过程近似滑窗从而有了Fast RCNN算法。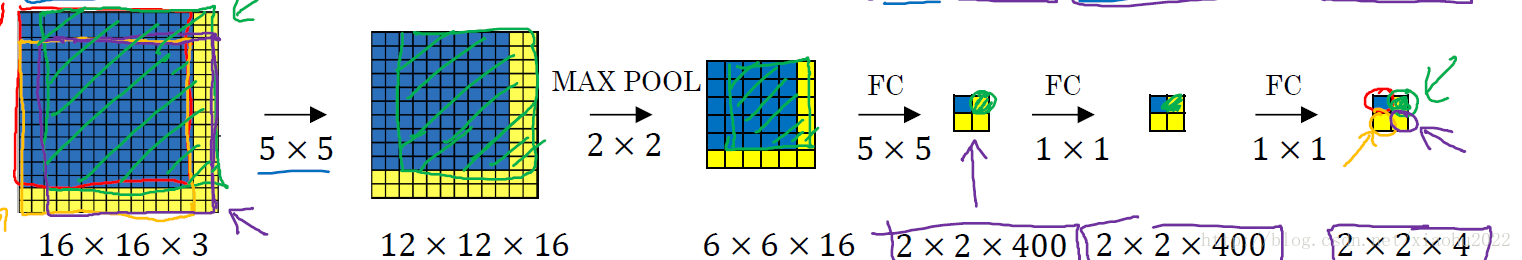
再演变至以
anchor box为代表的Faster RCNN、SSD和YOLO等系列算法,其原理在于可以对每一个ROI区域的中心,给定一个假设的长宽比,由此作为候选区域,再在后面利用回归层精修回归框。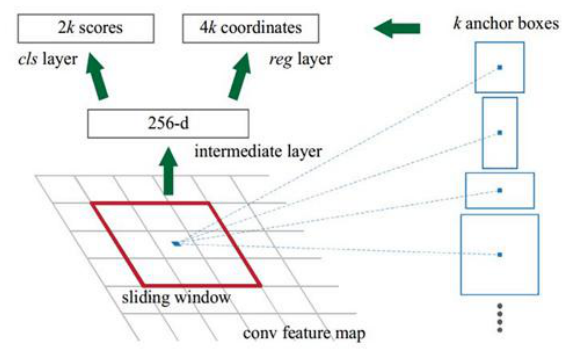
最后到现在的
Corner为代表的CornerNet算法,不断地提升候选框提取效率、候选框有效率、候选框精准度以及与分类框架的融合。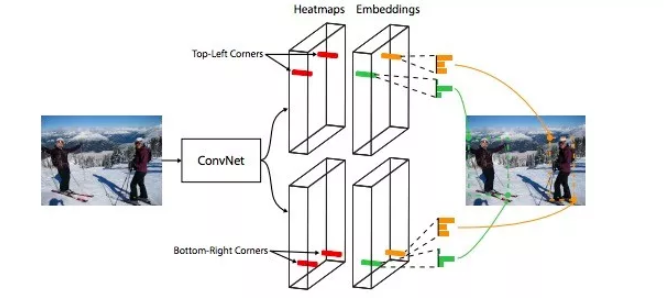
判断目标属于什么类别。有了候选区域,那么就可以利用很简单的级联全连接层判定每个候选区域属于前景/背景的概率,以及属于各个目标类别的概率。
目标精定位。目标框的描述包括目标的中心/角点位置和宽高,这些仅仅依赖候选区域是不够精确的,那么就需要合理的设计损失函数,利用多个全连接层进行进一步的回归,得到目标框的精修位置。当然CornerNet里面采用骨骼关键点检测里面的Hourglass结构作为backbone,再加上Corner Pooling层预测角点位置,不存在精修。
2.Darknet
2.1 Darknet网络框架
目前来说,无论是在目标检测、目标识别还是目标分割、姿态分析等领域,都会用到各种各样的backbone网络,最常用的就是基于图像分类的backbone网络,因为深度学习本质是分类,而绝大多数分类网络都会在ImageNet竞赛中进行测试,我们从AlexNet,VGGNet到GoogleNet,再到ResNet/DenseNet等,已经见过很多优秀的骨干网络结构了,其中很多优秀的子模块也被用于其他网络结构,如:卷积+池化+BatchNorm+Relu的组合、Inception各个版本结构、残差模块、1x1卷积核等等。
而Darknet实际上也是YOLO作者实现的一个backbone网络,其改进对象主要是GoogleNet,将GoogleNet中的Inception结构改成了串行的结构,从而使得网络速度更快,而效果仅仅损失了一点。可以看到下面的网络结构有24个卷积层,外加2个全连接层。

2.2 Darknet训练框架
除此之外呢,Darknet也是一个深度学习框架,其框架设计与caffe基本一致,只不过是用C语言写的,其整体框架十分简洁,所以编译速度非常快。如果学习过caffe的话,应该很容易上手darknet。其中darknet.h就类似于caffe中的caffe.proto,定义了所有数据结构,而网络的构建是利用了cfg格式文件,即利用key=value方式搭建网络,这种方式的问题在于对于复杂网络的设计非常复杂,很难写。另外,由于darknet是纯C框架,所以要想增加自定义层的话会比较麻烦,主要是因为没有好的设计模式和面向对象设计,导致使用者需要完全读懂整个框架,而且很难实现共享内存和逐层不同学习率。
当然,darknet框架的安装也是很简单的,除开显卡驱动和CUDA、cudnn等配置之外,只需要从git上面clone下来源码,然后make即可,这里我们不考虑Windows版本的,github上面有相应的教程。不仅可以利用原始的C接口,还能利用将其编译为动态链接库供C++接口调用,见这里,不过我主要是利用python接口调用,这里呢就存在一个问题,即原始darknet数据结构是image,如果利用ctypes进行C/Python混合编程的话,需要设计到numpy数据结构与image数据结构的交互,即:
1 | from ctypes import * |
上面这种利用图像数据结构转化的方式,会占用很多时间,所以我们可以利用numpy的c接口实现数据结构转换,具体如下:
先在src/image.c line 558左右添加:
1 |
|
然后在src/image.h19行左右添加:
1 |
|
再在MakeFile中加入:
1 | ifeq ($(NUMPY), 1) |
并设置Makefile
1 | GPU=1 |
最后python接口为:
1 | def nparray_to_image(self,img): |
这样的话,数据转换的速度大大提升,下面我附上我写的darknet.py:
1 | from ctypes import * |
3.YOLOv1
3.1 YOLO网络框架
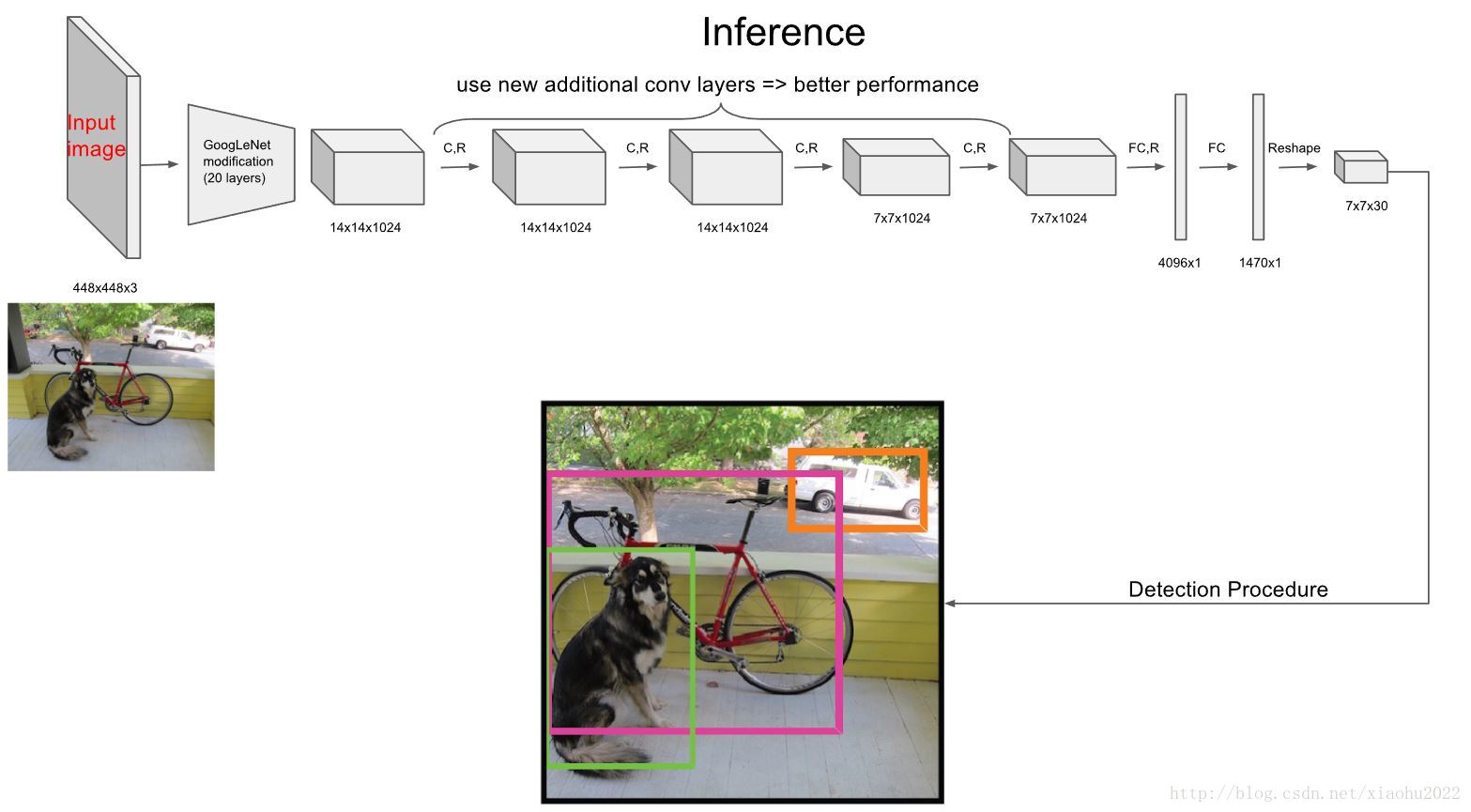
作者为了让backbone网络具有更好的性能,取了上面提到的darknet版本的前20个卷积层,然后利用一个全局池化层和一个全连接层,搭建了一个预训练网络,其中全局池化层是指的将一个通道内的所有元素平均,这一点在YOLO系列版本中都有体现:
可以看到YOLOv1才用的darknet版本(Darknet Reference)效果最差,其余的我们后面再说。有了预训练模型之后,我们再以上面提到的Darknet的完整框架(24卷积层+2全连接层)进行训练,其中网络输入大小固定为448x448。然后将最后一层的输出形状改为7x7x30。
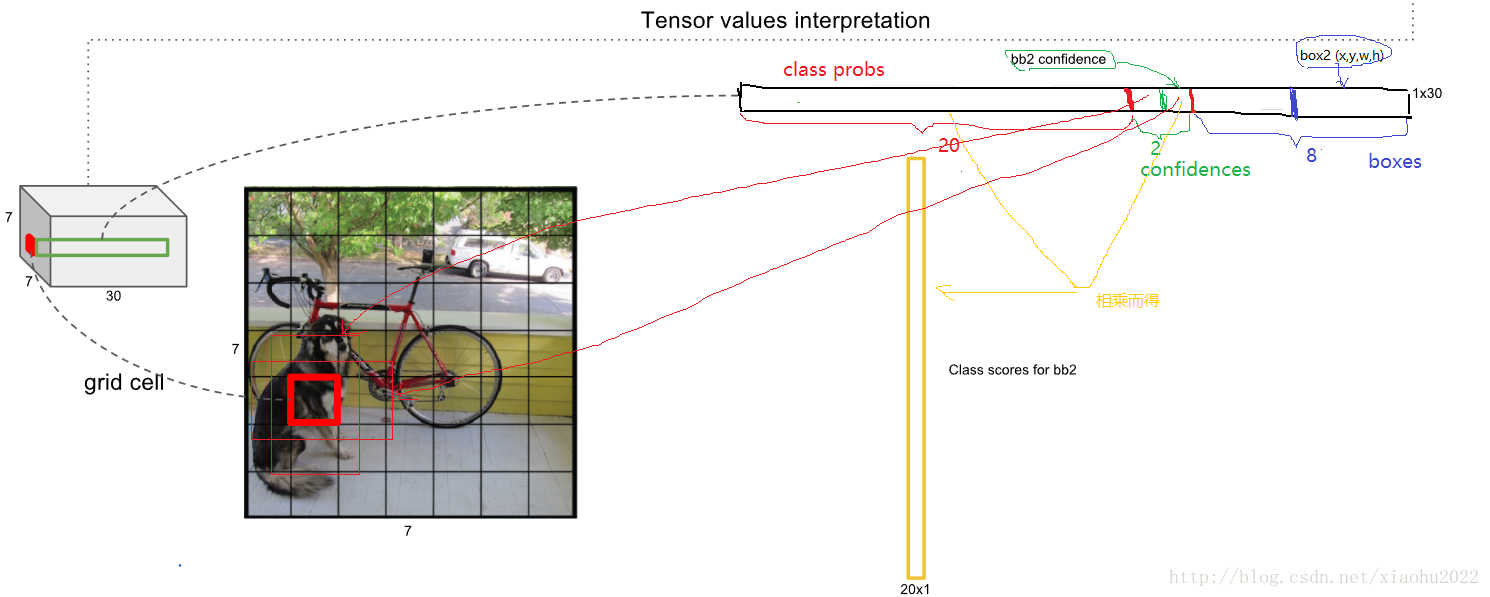
对于网络的输出,我们可以这样理解,30=20+2+4x2,其中20指的是VOC数据集的类别数,即20个类别的概率,2指的是两个目标框的置信度,然后每个通道预测2个目标框,所以就是两个(x,y,w,h)即8个元素。那么作者在论文中所提到的网格划分是怎么体现的呢,这里要通过最后一个卷积层的输出来看,即7x7x1024,可以看到特征图的尺寸是7x7,那么根据卷积网络的特点,每一层的输出特征图上的每一个像素点都会对应着输入特征图的一个区域,也就是这个像素点的感受野,那么在最后一层卷积层输出特征图上,也是如此,所以我们可以认为是将原图划分成了7X7的网格区域,每个网格预测20个类别的概率,目标框置信度以及两个目标框信息,其中每个目标的中心位置都会转换至网格区域内。
另外要说明的是,我在最新的github版本中发现,最后两个全连接层被替换成了:
1 | [local] |
其中的connected不用多说,就是全连接层,只不过节点数变成了1714,即7x7x35,那么这个35则说明每个网格区域会输出:20个类别概率,3个目标框置信度,3个目标框信息包含(x,y,w,h)。对于每个框所包含的物体判别方式则是采用了贝叶斯公式,将上述各个类别的概率作为条件概率。因此每个类别的真实置信度计算方式如下:
也就是说每个目标框所输出的边框置信度,本身就包含了先验概率和IOU的乘积,这一点在YOLOv2论文中有所体现。另外我们还发现YOLOv1中是直接输出目标框的,而不是采用anchor boxes方式。
而local是用的Locally Connected Layers结构,这种结构跟1x1卷积方式不同,1x1卷积核是利用很多个1x1大小的卷积核遍历整个特征图,而Locally Connected Layers结构则是一个介于全连接和卷积网络之间的一个结构:

可以看到,它也是利用卷积的方式进行计算的,不同的地方在于随着卷积的不断遍历,每个遍历位置的卷积核都不一样,即没有了卷积层所特有的共享内存。其好处在于更多的利用了空间相对区域特征以及整体特征,从而提升了一点效果。
3.2 数据准备
目前最常用的两个目标检测数据集分别是VOC和COCO,其中VOC数据集中的目标多为大目标,分为20个类别,而COCO数据集中有很多小而密集的目标,更加贴近实际,共80个类别,有几十万幅图像,几百万个目标实例。
对于YOLO的训练,我们需要将每个目标的信息进行转化,其中一个文件中包含所有目标信息:
1 | <class_label,center_x,center_y,width,height> |
其中目标框信息都需要归一化,即除以对应的图像宽高,另一个文件中则是包含对应图像的地址。
3.3 数据增强
作者在训练中主要采用了 jittering 和 HSV 空间扰动两种数据增强方式,详细的过程比较复杂,我用 matlab 把过程复现了:
1 | clc;clear;close all; |
作者在 YOLO 和 YOLOv2 分别用了两种实现方法,第一种将 jittering 和 resize 分开了,采用双线性插值的方式,第二种则是将二者结合了,先在原图获取一定比例的亚像素值,然后再进行随机双线性插值,效果如下:

可以看到,方式一的 jittering 会将边界像素进行复制扩充,并且不会内部像素会进行重排,所以是各向异性 resize。而方式二就好像在保证原始图像比例的前提下,通过填充 0 像素达到规定尺寸,所以是各向同性 resize。然后随机将图像进行左右翻转,最后就是 HSV 空间扰动,具体原理还是直接看代码,由于每次随机的值都不一样,所以下面的图可能与上面的不是一致的:

3.4 训练技巧
YOLO训练过程中采用了很多技巧,具体如下:
采用Leaky Relu激活函数
损失函数
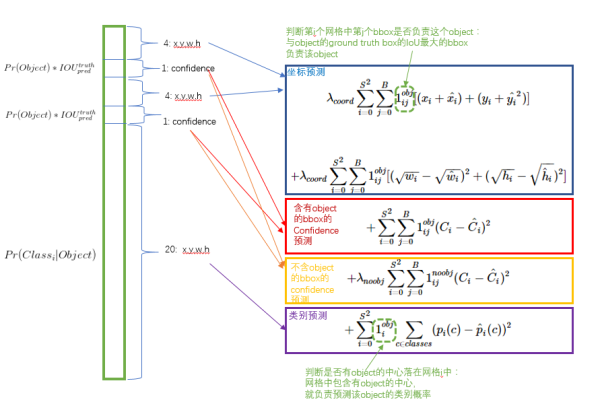
损失函数整体分为定位误差和分类误差(图中的中心位置x,y部分有错误),其中
(1)第一部分表示当区域内存在目标,且也检测到了匹配目标的前提下,计算目标框中心的均方误差,定位权重为5;
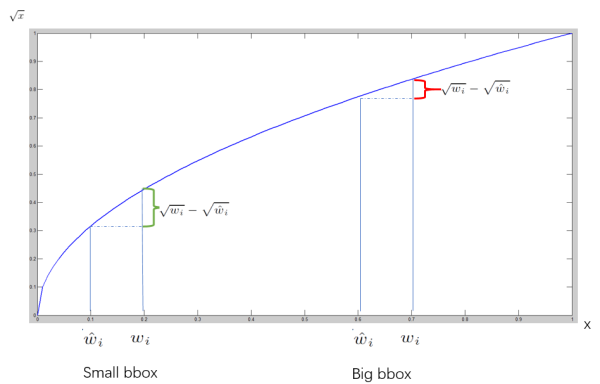
(2)第二部分就是当区域内存在目标,且也检测到了匹配目标的前提下,计算的目标框宽高的均方误差,定位权重为5,实际上作者训练的时候输出的就是宽高开平方后的结果。这里注意用宽和高的开根号代替原来的宽和高,这样做主要是因为相同的宽和高误差对于小的目标精度影响比大的目标要大。举个例子,原来 w=10,h=20,预测出来 w=8,h=22,跟原来 w=3,h=5,预测出来其实前者的误差要比后者下,但是如果不加开根号,那么损失都是一样:4+4=8,但是加上根号后,变成 0.15和 0.7;
(3)第三部分是分别计算当区域内真实目标和与之匹配的预测目标同时存在和不同时存在的情况下,边框置信度的均方误差,其中${\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}}
\over C} _i}$表示的是真实目标框与预测目标框的IOU值。然而,大部分边界框都没有物体,积少成多,造成loss的不平衡,所以同时存在状态下的分类权重为1,不同时存在状态下的分类权重为0.5;(4)第四部分计算的是当该区域存在目标时,计算目标类别均方误差。对于每个格子而言,作者设计只能包含同种物体。若格子中包含物体,我们希望希望预测正确的类别的概率越接近于1越好,而错误类别的概率越接近于0越好。
其中对于预测目标和groundtruth的匹配,作者除了利用IOU进行匹配之外,对于无匹配对象的ground,则是取与其(x,y,w,h)均方误差最小的目标框作为匹配对象
非极大值抑制
非极大值抑制(NMS)算法是目标检测领域中不可或缺的一个算法,其主要功能在于目标去重。而主要依据在于目标框之间的IOU以及每个目标框的置信度,即保证在IOU较大的目标群中选择置信度最高的目标框作为该目标群唯一的预测输出。
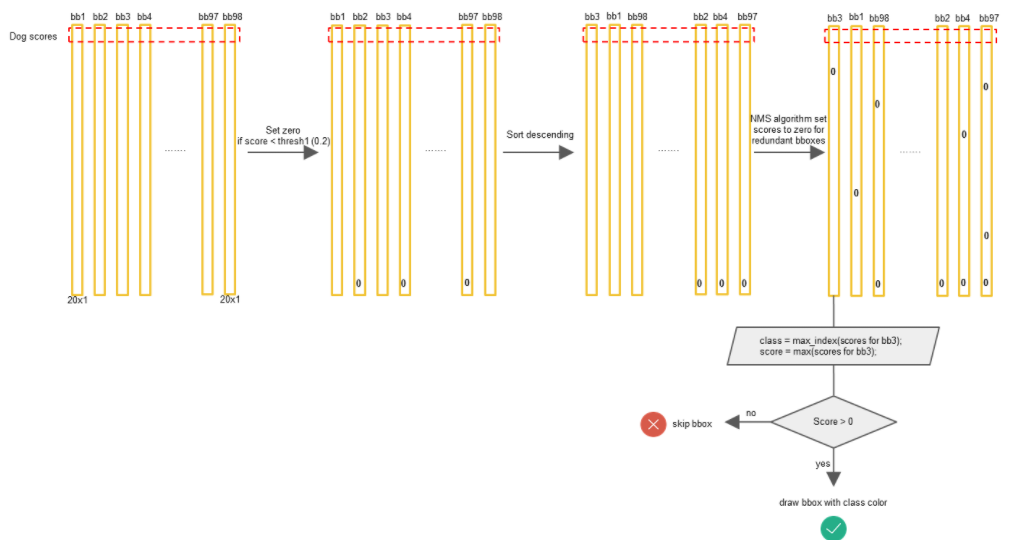
YOLO所采用的NMS算法流程如下:
Step1 在网络输出结果之后,会得到7x7x2=98个目标框,首先会根据阈值将prob不合格(大概率属于背景)的目标框置信度置为0;
Step2 对于每一个类别分开处理,先根据每个目标框在该类别下的prob置信度进行从大到小排序;
Step3 对于排序好的第一个置信度不为0的目标框,依次计算与其他置信度不为0的目标框的IOU,如果IOU大于阈值,则将该目标框置信度置为0,且其对应的所有类别prob都置为0;
Step4 转移至下一个置信度不为0的目标框,重复Step3,直到下一步没有置信度非0的目标框为止;
Step5 重复Step2
Step5 输出所有置信度非0的目标框,并根据阈值筛选有效目标。
部分C代码如下:
1 | int nms_comparator(const void *pa, const void *pb) |
这里要注意的是YOLOv1中并没有用到softmax,所以可能同一个目标框的多个类别的置信度都很高。
dropout
为了减少过拟合概率,YOLOv1中采用的是dropout方式,即在第一个全连接层/局部连接层后利用dropout随机将特征图中的一部分特征丢失。
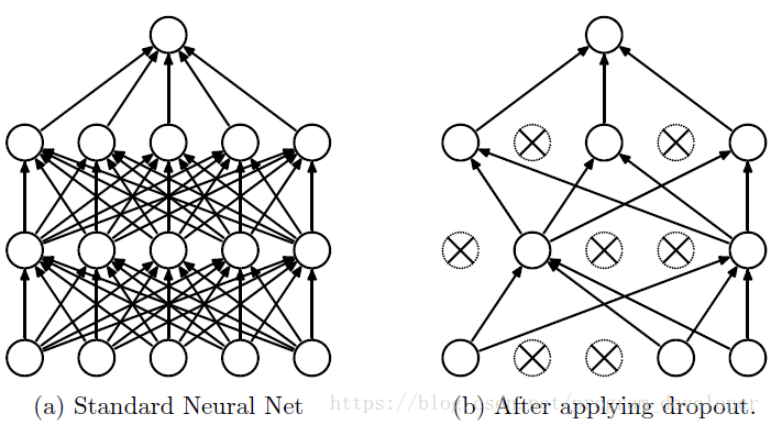
关于dropout的实现,其主要依据的是
drop_probability,即丢失比例/概率,不同框架的实现方式不同,例如caffe:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17template <typename Dtype>
void DropoutLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
unsigned int* mask = rand_vec_.mutable_cpu_data();
const int count = bottom[0]->count();
if (this->phase_ == TRAIN) {
// Create random numbers
caffe_rng_bernoulli(count, 1. - threshold_, mask);
for (int i = 0; i < count; ++i) {
top_data[i] = bottom_data[i] * mask[i] * scale_;
}
} else {
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
}其在测试环节直接将输入映射到输出,而在训练环节则是利用伯努利分布按照
1-drop_probability的比例选取特征图中的特征,得到一个mask,然后乘以一定比例:而在Darknet中,其实现方式是:
1
2
3
4
5
6
7
8
9
10
11void forward_dropout_layer(dropout_layer l, network net)
{
int i;
if (!net.train) return;
for(i = 0; i < l.batch * l.inputs; ++i){
float r = rand_uniform(0, 1);
l.rand[i] = r;
if(r < l.probability) net.input[i] = 0;
else net.input[i] *= l.scale;
}
}实现原理是一样的,不过其实现方式更加清晰,缺点在于需要重复生成很多无效随机数,以及没有向量加速。
学习率
YOLOv1采用的是
multistep变化方式,即在特定的迭代次数更新学习率,论文中的YOLOv1采用的是学习率逐渐衰减的方式,但有意思的是最新的YOLOv1中学习率变化过程不同于传统的逐渐衰减方式,而是类似于当前新兴的warmup/warmrestart变化方式。我们知道传统的训练模式下: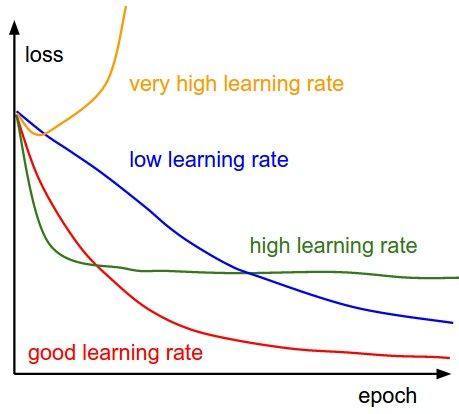
不断衰减的学习率可以稳定收敛,但是现在发现在某些模型训练过程中收敛效果并不好,所以就有研究者提出了“热重启”策略,当然也有类似的“循环”策略:
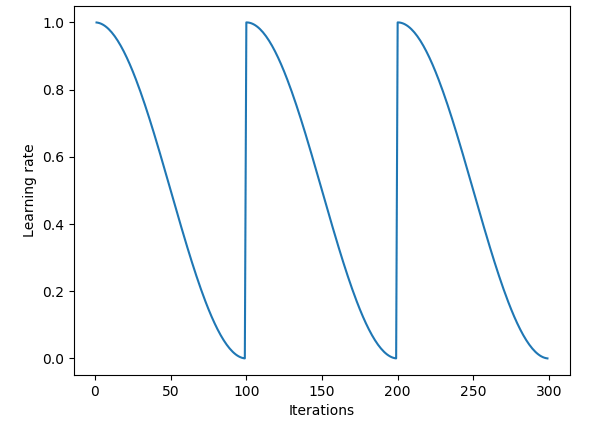
那么在YOLOv1中的学习率设定是:
1
2
3
4learning_rate=0.0005
policy=steps
steps=200,400,600,20000,30000
scales=2.5,2,2,.1,.1可以看到,初始学习率只有0.0005,先慢慢增大,然后逐渐变小。
3.5 测试效果
先放一张原论文中的实验效果图:
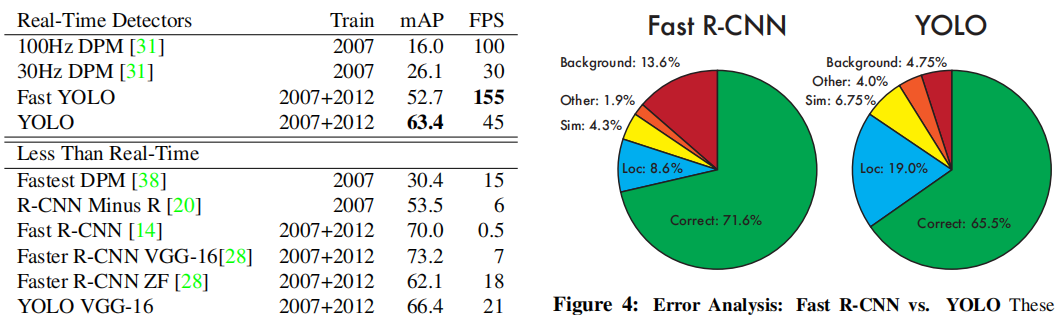
我们可以看到YOLOv1这个典型的one-stage目标检测算法,在速度大幅领先的前提下,只损失了7%的精度,并且值得注意的是YOLO相对于Fast RCNN将目标误识别为背景的概率小很多,所以作者做了一个小尝试,即以YOLO本身预测为主,逐个对比Fast RCNN和YOLO预测的目标框,根据置信度进行选择,也就是下面Fast R-CNN + YOLO的embedding组合。那么对于VOC各个类别的定位精度:
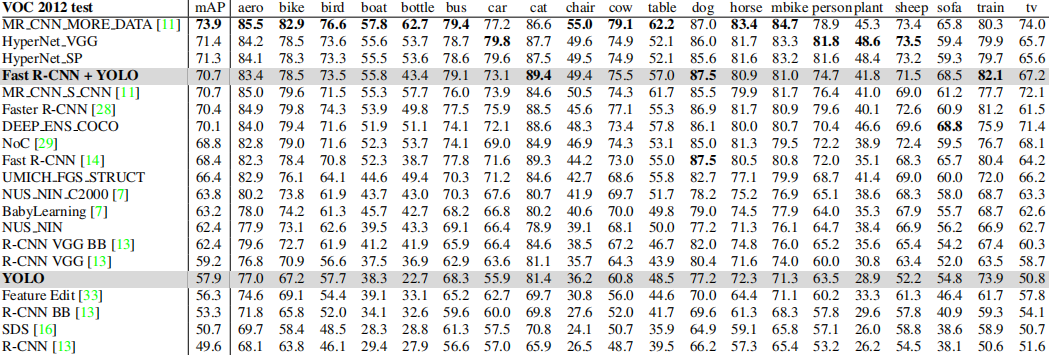
其对于稀疏大目标的定位效果还是能接受的:

3.6 优缺点
YOLO的优点不用多说,其作为当时最快的实时目标检测算法横空出世,SSD是在其后出来的,正式打开了one-stage目标检测算法的大门,虽然精度仍然不如Faster RCNN等,但是其速度很高,适合工程界研究改造。
当然其缺点也有很多:
1.YOLOv1采用了7x7的网格划分模式,每个网格只能预测两个同类别的目标框,那么就无法预测密集场景下的目标位置,如:拥挤人群;
2.YOLOv1的网格划分方式会影响每个目标的边界定位准确度,因为目标一般是跨网格区域的,如果目标只有一小部分在某个网格,那么可能就会被忽略;
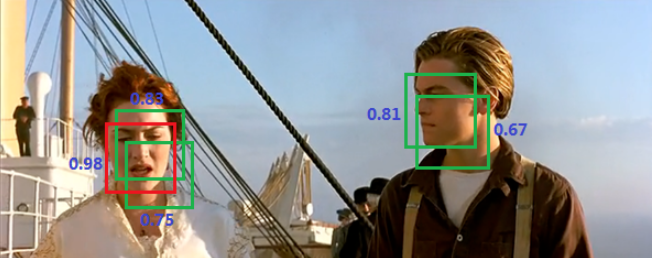
3.NMS本身漏洞,NMS会将相邻的目标框去重,那么就会出现下面的情况:

另外,由于置信度和IOU并不是强相关的,那么对于下面的情况,则不得不选择更差的目标框:

4.固定分辨率,由于YOLOv1中存在全连接层,所以输入的分辨率必须固定,那么对于YOLOv1所固定的448x448大小分辨率,很多大分辨率图像中的目标会变得很小,另外许多非正方形分辨率的图像目标会失真。
4.YOLOv2
YOLOv2也被称作YOLO9000,其相对于YOLOv1提升了很多,正如作者所说:Better、Faster、Stronger。其行文很容易理解,我们直接通过创新点来了解其与YOLOv1的区别。
4.1 网络结构改变
YOLOv2的网络结构做了较大的改变,主要有:
Training for classfication—Darknet19
YOLOv2在YOLOv1中的backbone网络基础上借鉴了VGG网络中的卷积方式,利用多个小卷积核替代大卷积核,并且利用1x1卷积核代替全连接层,这样做的好处的特征图每个位置共享参数,然后利用卷积核个数弥补参数组合多样性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27layer filters size input output
0 conv 32 3 x 3 / 1 256 x 256 x 3 -> 256 x 256 x 32 0.113 BFLOPs
1 max 2 x 2 / 2 256 x 256 x 32 -> 128 x 128 x 32
2 conv 64 3 x 3 / 1 128 x 128 x 32 -> 128 x 128 x 64 0.604 BFLOPs
3 max 2 x 2 / 2 128 x 128 x 64 -> 64 x 64 x 64
4 conv 128 3 x 3 / 1 64 x 64 x 64 -> 64 x 64 x 128 0.604 BFLOPs
5 conv 64 1 x 1 / 1 64 x 64 x 128 -> 64 x 64 x 64 0.067 BFLOPs
6 conv 128 3 x 3 / 1 64 x 64 x 64 -> 64 x 64 x 128 0.604 BFLOPs
7 max 2 x 2 / 2 64 x 64 x 128 -> 32 x 32 x 128
8 conv 256 3 x 3 / 1 32 x 32 x 128 -> 32 x 32 x 256 0.604 BFLOPs
9 conv 128 1 x 1 / 1 32 x 32 x 256 -> 32 x 32 x 128 0.067 BFLOPs
10 conv 256 3 x 3 / 1 32 x 32 x 128 -> 32 x 32 x 256 0.604 BFLOPs
11 max 2 x 2 / 2 32 x 32 x 256 -> 16 x 16 x 256
12 conv 512 3 x 3 / 1 16 x 16 x 256 -> 16 x 16 x 512 0.604 BFLOPs
13 conv 256 1 x 1 / 1 16 x 16 x 512 -> 16 x 16 x 256 0.067 BFLOPs
14 conv 512 3 x 3 / 1 16 x 16 x 256 -> 16 x 16 x 512 0.604 BFLOPs
15 conv 256 1 x 1 / 1 16 x 16 x 512 -> 16 x 16 x 256 0.067 BFLOPs
16 conv 512 3 x 3 / 1 16 x 16 x 256 -> 16 x 16 x 512 0.604 BFLOPs
17 max 2 x 2 / 2 16 x 16 x 512 -> 8 x 8 x 512
18 conv 1024 3 x 3 / 1 8 x 8 x 512 -> 8 x 8 x1024 0.604 BFLOPs
19 conv 512 1 x 1 / 1 8 x 8 x1024 -> 8 x 8 x 512 0.067 BFLOPs
20 conv 1024 3 x 3 / 1 8 x 8 x 512 -> 8 x 8 x1024 0.604 BFLOPs
21 conv 512 1 x 1 / 1 8 x 8 x1024 -> 8 x 8 x 512 0.067 BFLOPs
22 conv 1024 3 x 3 / 1 8 x 8 x 512 -> 8 x 8 x1024 0.604 BFLOPs
23 conv 1000 1 x 1 / 1 8 x 8 x1024 -> 8 x 8 x1000 0.131 BFLOPs
24 avg 8 x 8 x1000 -> 1000
25 softmax 1000我们可以看到其中有19个卷积层和5个
max pooling层,所以称其为Darknet19。作者利用该网络重新再Imagenet上训练了,相对于yolov1中的backbone网络,参数量更少,计算速度更快,效果更好。Training for Detection
有了backbone骨干网络之后,作者剔除了
Darknet19的最后一个卷积层,然后额外添加了几个卷积层:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[route]
layers=-9
[convolutional]
batch_normalize=1
size=1
stride=1
pad=1
filters=64
activation=leaky
[reorg]
stride=2
[route]
layers=-1,-4
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=425
activation=linear我们可以看到其中出现了两个新层
reorg和route,这两个层的意义在于: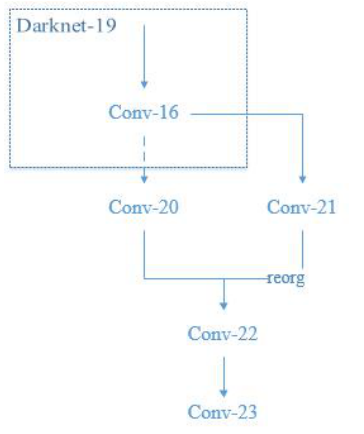
可以也就是说,
route的层的作用就是将选定层按照通道拼接在一起,而reorg层的作用就是将特征图均匀划分为 4 份,从而使得两组特征图可以拼接。大致原理如下:
最终的网络结构为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32
1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32
2 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64
3 max 2 x 2 / 2 208 x 208 x 64 -> 104 x 104 x 64
4 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
5 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64
6 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
7 max 2 x 2 / 2 104 x 104 x 128 -> 52 x 52 x 128
8 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
9 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
10 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
11 max 2 x 2 / 2 52 x 52 x 256 -> 26 x 26 x 256
12 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
13 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
14 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
15 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
16 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
17 max 2 x 2 / 2 26 x 26 x 512 -> 13 x 13 x 512
18 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
19 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
20 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
21 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512
22 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
23 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024
24 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024
25 route 16
26 reorg / 2 26 x 26 x 512 -> 13 x 13 x2048
27 route 26 24
28 conv 1024 3 x 3 / 1 13 x 13 x3072 -> 13 x 13 x1024
29 conv 425 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 425
30 detection这里输出的425指的是:每个网格输出5个目标框,每个目标框包含COCO的80个类别概率,一个边框置信度,以及(tx,ty,tw,th),即5x(80+1+4)。
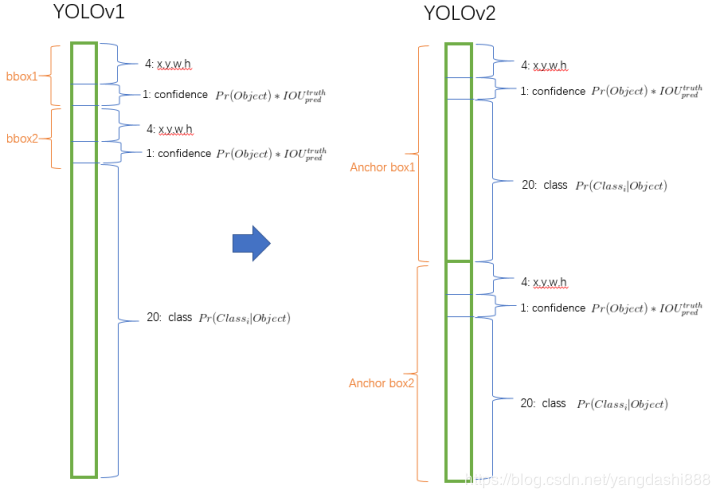
全卷积网络
综上可知,YOLOv2是一个全卷积网络,与YOLOv1相同,利用感受野的概念,我们可以认为是将原图划分为了多个网格区域,且区域半径为32,所以说输入大小必须是32的倍数。另外全卷积网络的好处在于可以有任意分辨率的输入,因为全连接层参数依赖前后两层的尺寸,而卷积层参数只有卷积核,与前后层尺寸无关,所以更为方便了。
4.2 batch normalization
相对于YOLOv1,YOLOv2将dropout替换成了效果更好的batch normalization,在每个卷积层计算之前利用batch normalization进行批归一化:
4.3 Multi-Scale Training
为了让网络能适应不同分辨率的输入,在训练过程中,每个10个batches会随机选择一种分辨率输入,即利用图像插值对图像进行放缩,由于训练速度的要求以及分辨率必须是32倍数,所以训练过程中选择的分辨率分别为:320, 352, …, 608。
4.4 Anchor boxes
YOLOv2相对于YOLOv1的定位架构最大的改变在于剔除了anchor boxes概念,具体见第一章,从直接预测目标相对网格区域的偏移量到预测anchor box的修正量,有了先验长宽比的约束,可以减少很多不规则的目标定位。
其中,p代表的是anchor box的先验值,c表示每个网格区域的左上角顶点,t表示网络输出的目标框的5个参数(tx,ty,tw,th,to),b表示真实预测定位信息。而最后一个关于先验概率的等价关系我们可以知道,与YOLOv1相同,这里目标预测的边框置信度包含了IOU先验值。
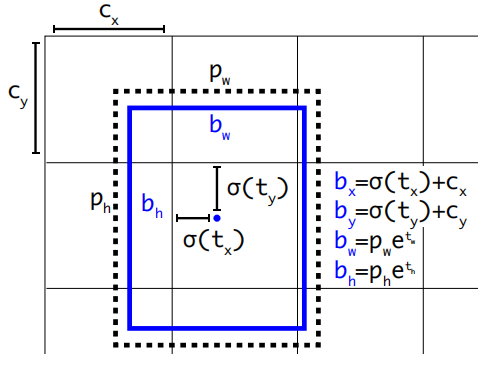
其中对于部分输出进行了logistic转换:
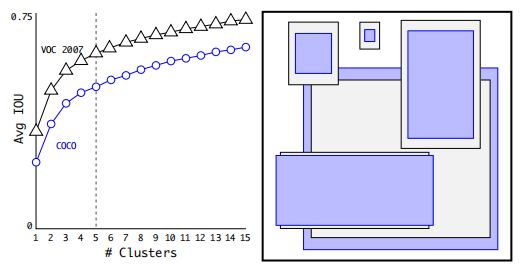
对于先验anchor boxes的确定,作者通过 K-means 的方法对 VOC 和 COCO 数据集所有框的标签进行聚类,最后发现anchor box 在仅有 5 种 aspect ratio 的情况下就能达到足够的效果,当然,作者也试着将 K 提升到 9 个,发现效果更好。
4.5 其他训练技巧
softmax
YOLOv2中对于每个类别的概率输出进行了softmax归一化。
学习率
YOLOv2的学习率变化方式与YOLOv1类似:
1
2
3
4
5
6learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1只不过多了一个
burn_in参数,那么上面的参数设置对应的变化方式为:损失函数
YOLOv2的损失函数类似于YOLOv1,也有所不同,我阅读源码之后总结如下:
可以发现只有定位误差部分的损失函数变化了,其中${\lambda {prior}=0.01},{\lambda {coord}=1},{\lambda {class}=1},{\lambda {obj}=5,{\lambda _{noobj}=1}}$,其中第一部分的意思是当训练的batch数不超过12800个时,尽量让预测目标框靠近每个网格中心,且尺寸与先验anchor box相同。
4.6 联合训练分类和检测
作者在论文最后提出,可以将分类和检测数据集放在一起训练网络,在遇到分类问题时,就只调用分类部分损失函数,否则调用检测分布损失函数。而对于两类数据集中存在的,类别相互包含的情况,作者则是剔除了Word Tree的概念:
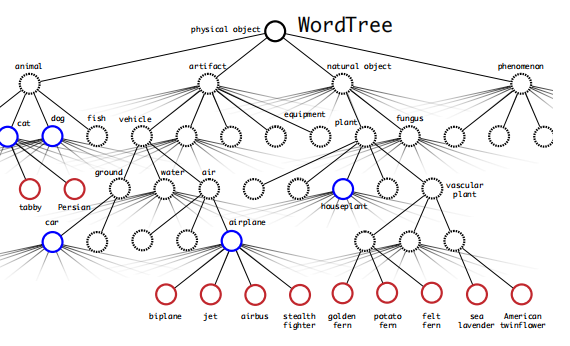
其原理实际上就是,预先构建好所有类别的关系树,然后利用联合概率分布和条件概率等,进行组合,相当于YOLO中对于分类概率和目标置信度的关系。
4.7 测试效果
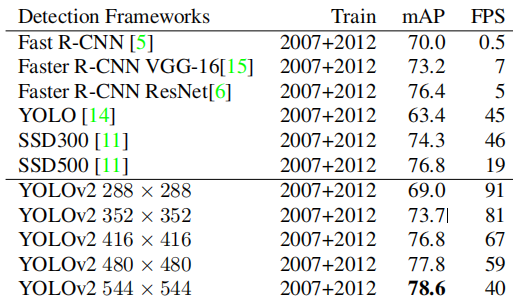
YOLOv2在VOC和COCO上的测试结果如下:
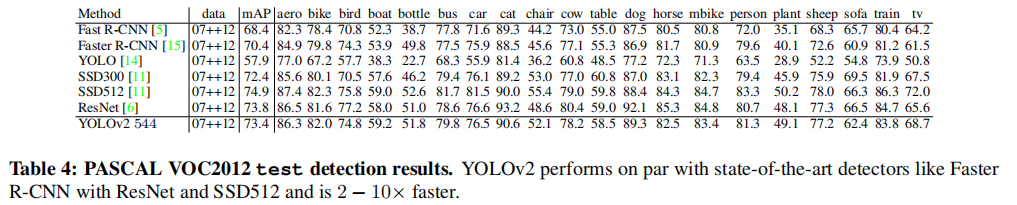
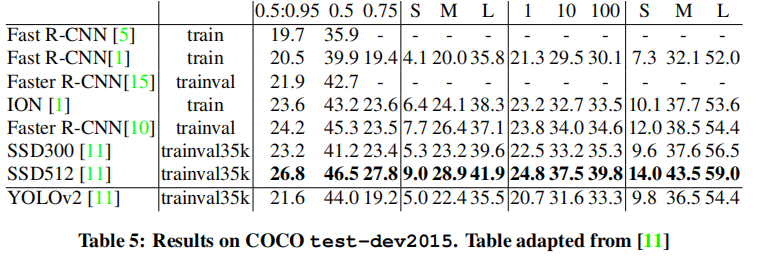
我们可以看到,此时的YOLOv2的效果已经与Faster RCNN以及新出现的one-stage算法SSD持平,不过YOLOv2依旧保持着遥遥领先的速度优势。
4.8 优缺点
YOLOv2相对来说在每个网格内预测了更多的目标框,并且每个目标框可以不用为同一类,而每个目标都有着属于自己的分类概率,这些使得预测结果更加丰富。另外,由于anchor box的加入,使得YOLOv2的定位精度更加准确。不过,其对于YOLOv1的许多问题依旧没有解决,当然那些也是很多目标检测算法的通病。那么随着anchor box的加入所带来的新问题是:
anchor box的个数以及参数都属于超参数,因此会影响训练结果;由于
anchor box在每个网格内都需要计算一次损失函数,然而每个正确预测的目标框才能匹配一个比较好的先验anchor,也就是说,对于YOLOv2中的5种anchor box,相当于强行引入了4倍多的负样本,在本来就样本不均衡的情况下,加重了不均衡程度,从而使得训练难度增大;由于IOU和NMS的存在,会出现下面的情况:
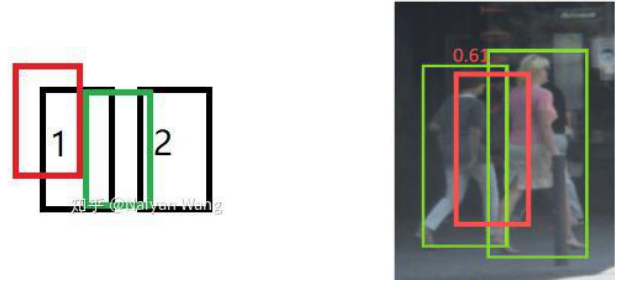
我们可以看到,当两个人很靠近或重叠时,检测框变成了中间的矩形框,其原因在于对于两个候选框(红,绿),其中红色框可能更加容易受到目标1的影响,而绿色框会同时收到目标1和目标2的影响,从而导致最终定位在中间。然后由于NMS存在,其他的相邻的框则会被剔除。要想避免这种情况,就应该在损失函数中加入相关的判定。
5.YOLOv3
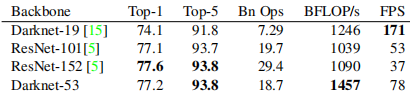
5.1 Darknet-53
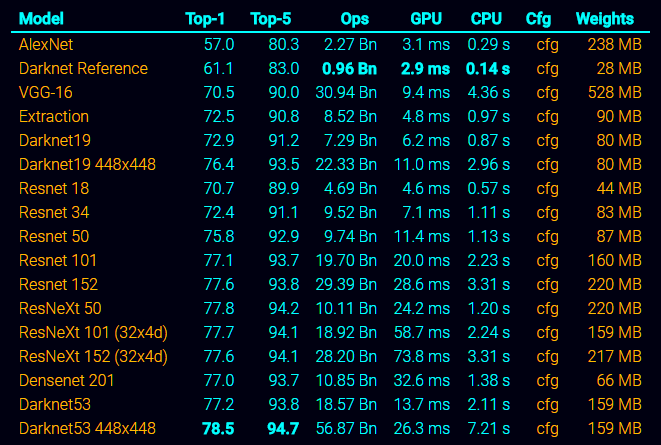
YOLOv3中又提出了一种新的backbone网络——Darknet-53,其效果还是见第二章的表格图片。其架构如下:
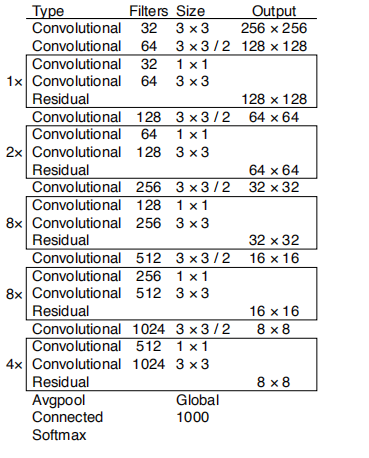
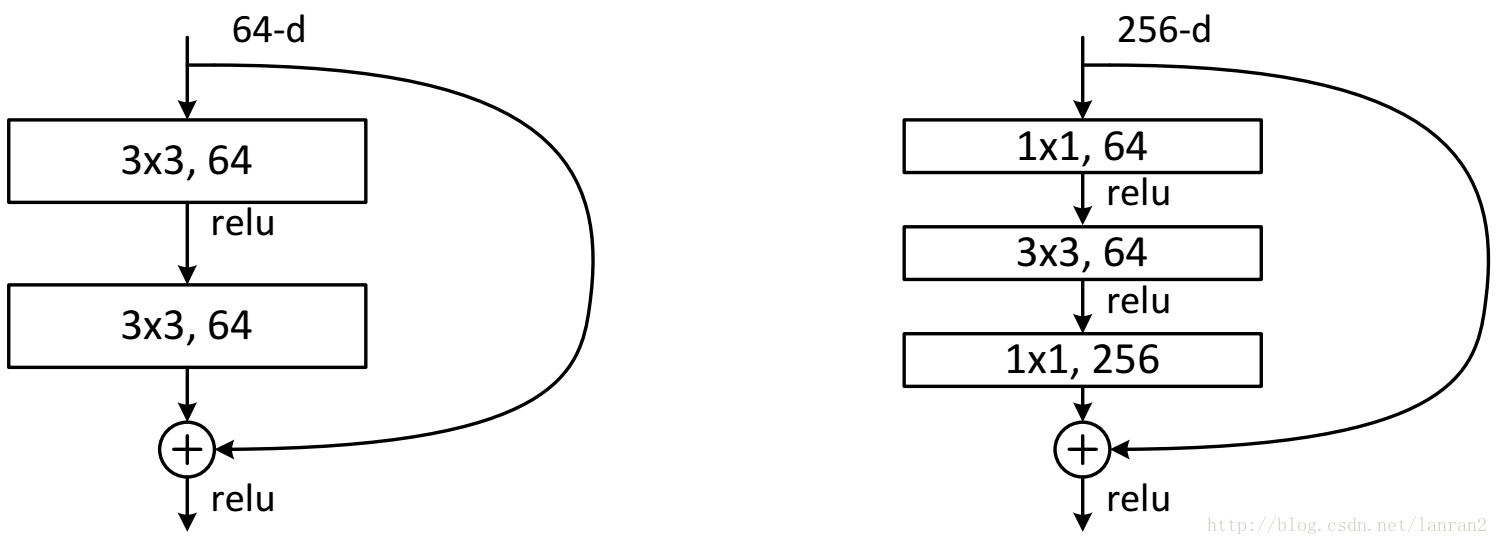
可以看到,新增了Residual模块,不同于原本的Resnet中的残差模块:
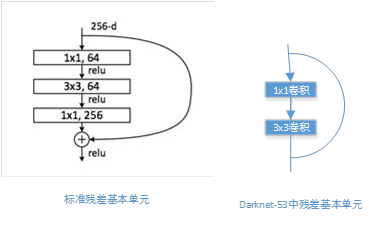
我怎么感觉作者就是为了加深网络,所以才不得不引入残差模块的…可以看到明显的效果变化:
5.2 网络多尺度输出
YOLOv3增加了top down 的多级预测,解决了yolo颗粒度粗,对小目标无力的问题。
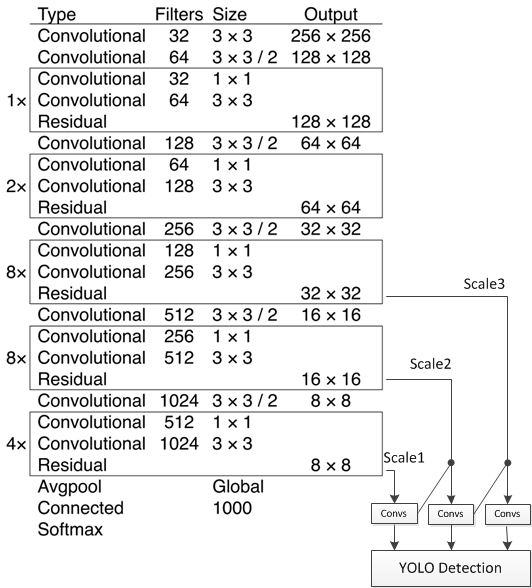
可以看到,不仅在不同的感受野范围输出了三种尺度的预测结果,每种预测结果中每个网格包含3个目标框,一共是9个目标框。而且,相邻尺度的网络还存在着级联:
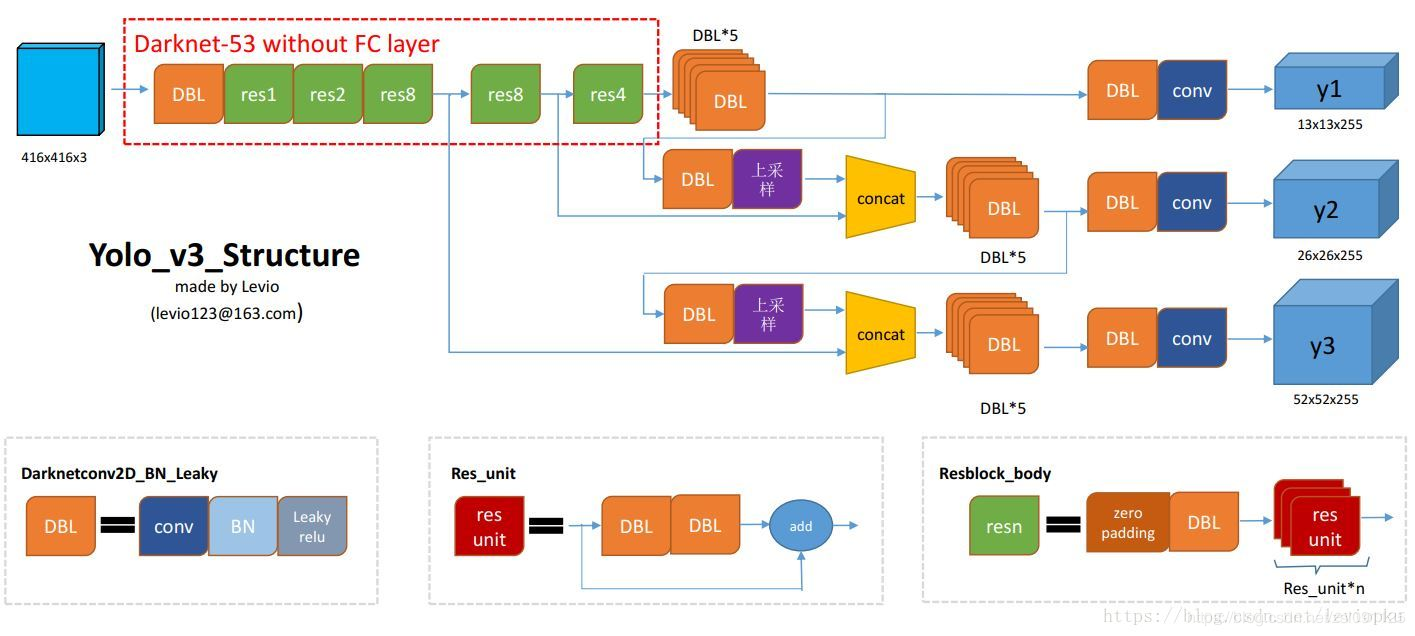
DBL: conv+BN+Leaky relu。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
upsample:终于把原来的reorg改成了upsample,这里的upsample很暴力,很像克罗内克积,即:
可以看到每个输出的深度都是255,即3x(80+5)。这种多尺度预测的方式应该是参考的FPN算法。
5.3 Anchor Boxes改进
YOLOv2中是直接预测了目标框相对网格点左上角的偏移,以及anchor box的修正量,而在YOLOv3中同样是利用K-means聚类得到了9组anchor box,只不过YOLOv2中用的是相对比例,而YOLOv3中用的是绝对大小。那么鉴于我们之前提到的anchor box带来的样本不平衡问题,以及绝对大小可能会出现超出图像边界的情况,作者加入了新的判断条件,即对于每个目标预测结果只选择与groundtruth的IOU最大/超过0.5的anchor,不考虑其他的anchor,从而大大减少了样本不均衡情况。
5.4 分类函数
YOLOv3中取消了对于分类概率的联合分布softmax,而是采用了logistic函数,因为有一些数据集的中的目标存在多标签,而softmax函数会让各个标签相互抑制。
5.5 测试效果
YOLOv3的泛化性能更好了:
在加入了多尺度预测之后,小尺度目标检测效果更好:

与其他算法的对比效果如下:
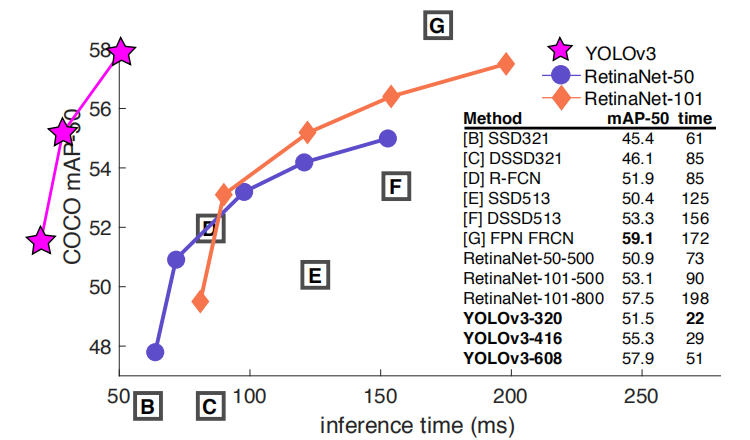
5.6 展望
感觉YOLOv3的提升已经很大了,不过一些固有问题还是没有解决,有意思的是,在加入了多尺度预测后,拥挤场景下的目标检测效果更好了。不过基于anchor box的目标检测算法始终都有着瓶颈,寻求更好的出路才是最好的。
参考资料
- http://lanbing510.info/2017/08/28/YOLO-SSD.html
- https://pjreddie.com/darknet/
- https://blog.csdn.net/m0_37192554/article/details/81092514
- https://blog.csdn.net/leviopku/article/details/82660381
- https://github.com/pjreddie/darknet
- Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. 2015.
- Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2017.
- Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[J]. 2018.

