前言
核相关滤波算法是单目标跟踪领域一个举足轻重的算法,而kernelized correlation filters(KCF)是其原始形态,下面我以一个小白的角度慢慢揭开其神秘面纱。
1.岭回归理论推导
岭回归的理论比较简单,类似于一个单层神经网络加上一个正则项,不同于支撑向量机中的结构风险最小化,岭回归更像是一个逻辑回归,是在保证误差风险最小的情况下尽量使得结构风险小。另外支撑向量机对于高维数据的训练比较快,因为它只取对分类有影响的 support 向量。不过在此处 KCF 的训练样本也不多,所以二者其实都可以,再加上 KCF 中岭回归还引用了对偶空间、傅里叶变换以及核函数,二者的差别就比较小了。
岭回归的算法形式如下:
其中X 为特征矩阵,w 为权值,y 为样本标签/响应,其中每一项都采用了L2 范数的平方,即矩阵内所有元素的平方和。因此,该优化的关键在于求最优的 w,求解方法则是使用了最直接的拉格朗日乘子法:
我们假设当前的权重W和输出y都是一维向量,则矩阵的求导公式满足:
不过,由于后面要引入复频域空间,所以我们这里做一些微调:
其中,H 代表共轭转置,即在转置的同时将矩阵内所有元素变为其共轭形式,原因很简单:
2. 循环矩阵
2.1 循环矩阵的引入
由于在目标跟踪中定位目标时如果采用循环移位的方式定位其中心,则需要采用循环的方式逐步判断,这样做太耗时,因此作者引入了循环矩阵。这样做的话,我们的待选目标框不用移动,直接将原图像矩阵循环移位。以一维矩阵为例:
矩阵的每一行相对上一行都向右移动了一位,这里举这个矩阵例子是有用意的,通过该矩阵的n阶形式,我们可以轻松的实现任意矩阵 X 的右移$XK^T$或者下移$KX$ ,如:
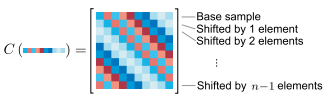
2.2 循环矩阵的转换
循环矩阵本身是将循环移位的结果整合到了一个矩阵中,虽然可以将循环计算过程优化为矩阵运算,但对于图像这类二维矩阵,则会生成一个很大的循环矩阵,从而耗费内存。这里作者巧妙地引入了离散傅里叶变换(DFT),将循环矩阵X等价为:
其中 F 与离散傅里叶变换中的矩阵有所差异,${\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}}
\over x} }$就是原矩阵的傅里叶变换,diag是将矩阵变为对角形式,后面会详细解释。
先以一维矩阵为例来证明:
Step1 定义循环矩阵 X 的多项式函数为:
这里先说明一下,单位矩阵 I 其实也是一个循环矩阵,而 $P^n $其实就是将矩阵I所有元素右移 n 个单位。
Step2 求矩阵K的特征值和特征向量:
可以发现矩阵 K 的特征矩阵与 DFT 的变换矩阵 W 一致,再利用多项式矩阵的性质可知,循环矩阵 X 的特征值为${f_X}\left( {diag\left( {{\lambda _k}} \right)} \right)$, 利用矩阵与其特征值矩阵相似的特点, 可以很容易的证明该性质。
Step3 求循环矩阵 X 的特征值和特征向量:
可以发现循环矩阵 X 的特征值就是其原矩阵 x 的离散傅里叶变换,对于循环矩阵的特征向量,推导过程如下:
在这里我们将 $D_k $替换为 DFT 变换矩阵W ,利用矩阵对角化可知:
Step4 利用 DFT 变换矩阵 W 的性质修正 X :
通过观察可知 W 为对称矩阵,另外也可以轻松证明${W^H}W = W{W^H} = nI$,在这里呢,我们可以对 W 进行适当地变换:
因此${F^H}F = F{F^H} = I$,则 F 为酉矩阵,同时它也满足 ${F^H} = {F^{-1}}$,如果我们将之前的 W 替换为 F ,那么:
所以整体来看, X 保持不变,综上可得公式(2-3)。
2.3 二维循环矩阵
上述推导都是基于一维矩阵进行的,那么对于二维矩阵的循环矩阵则是要进行两次一维的循环矩阵变换,下面简要介绍一下方法,完整的我不会推导~

对于 m×n 的矩阵 x,其循环矩阵是将其当作块矩阵,矩阵每一行的元素都是前一个元素向下平移得来的,每一列都是向右平移得来的。因此其循环矩阵大小为 mn×mn,这主要是为了将循环矩阵 X 变为方阵,这样才能求其特征值和特征向量。当然,如果原矩阵 x 本身就是方阵,那么则不必这样做,可以将行向量改为右移,列向量改为下移,这样就符合观察习惯,这也是论文代码所采用的方式。
先将 n×n 大小的矩阵 x 每一行向量单独看作一个 1×n 的块矩阵,按照一维循环矩阵$Kx$的逻辑去做,不断下移,可得一个 $n^2×n$的块矩阵。然后再将每一列向量单独看作一个$ n^2×1$ 的块矩阵,按照 $xK^T$的方式,不断右移,最后可得一个 ${n^2} × {n^2}$的块矩阵。其中二维的 DFT 变换方式为 $WXW^H$ 。
3. 循环矩阵与岭回归算法的结合
建立了循环矩阵 X 之后,如果判定其第(i, j)处的块矩阵处响应最大,即目标框相对前一个目标框向下偏移 i-1 个单位, 向右偏移 j-1 个单位。那么标签 y的大小也就是 n×n。将其与岭回归算法结合之后可以得到:
其中,${{{\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}} \over x} }^*}}$表示 x 经 DFT 变换之后的共轭形式,$\delta $表示全 1 向量,其等同于单位矩阵的特征向量,$\odot $表示矩阵元素点乘。
根据DFT时域卷积的性质:
而时域卷积常用的是循环卷积,即将原序列看作一个周期,通过验证可以得到:
可以发现${X^H} = C{\left( x \right)^H} = Fdiag\left( {{{\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}} \over x} }^*}} \right){F^H}$,因此可得:
利用上面的结论可以继续转换w为:
至此,权重矩阵 w 的求解在傅式空间变成了简单的点乘运算,运算复杂度大幅降低。
4. 对偶空间的引入
对偶空间的具体意义我只有一个模糊的概念,之前在运筹学中学习的时候就感觉对偶空间像是从另外一个角度分析优化问题,比方说岭回归中的权值矩阵w,它的目的是完成 X 到 y 的映射,如果将循环矩阵拉伸为多个行向量,即$n^2$个 n×n 的样本,则更直接一点就是完成从$ n^2$维空间到 1 维空间的维度转换。那么对偶空间呢?对偶空间所要考虑的就是那 $n^2$ 个样本对于问题的影响,而这个影响因子,在优化问题中常常作为约束惩罚项的系数,然后分别权衡约束对于各个样本的影响。
4.1 优化角度分析
原优化问题为:
其等价为:
采用惩罚函数的方式是:
可以发现,如果将${\xi _i}$ 看作${w_j}$经过一定线性变换之后在对偶空间的表现形式,则这里将其看作一个单独的变量,利用拉格朗日乘子法可得:
将其带入原目标函数可得:
由此可得原优化问题的对偶问题,将其转换成矩阵形式为:
其中 G 表示$\left\langle {{x_i},{x_j}} \right\rangle = {x_{i \cdot }}^T{x_{k \cdot }}$,利用拉格朗日乘子法可得:
再将此对偶空间的最优解带入公式(4-4)可得:
4.2 矩阵变换角度
上面的优化方法更侧重于从理论源头出发,而如果真的要用的话,可以直接用上面的理论,因此呢我们可以直接对矩阵进行变换:
4.3 新样本测试
训练好参数之后,当引入新样本时,可以直接利用 wx 的方式求出响应 y,根据公式(4-7)可得:
5.核函数的高维映射
5.1核函数的引入
核函数的引入主要是为了减少线性不可分问题的影响,因为岭回归跟神经网络或者深度学习不同,它是单层结构,需要从空间映射来着手。
常见的核函数有线性函数、多项式核函数和高斯核函数(RBF),而论文中则是采用了 RBF 核函数,理论上来讲是映射到了无穷维数的空间,可以通过展开其级数得知。
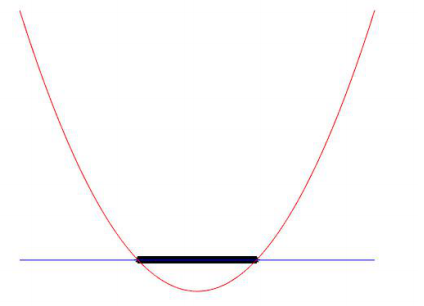
如图所示,黑色和蓝色区域明显是一个线性不可分的,而利用一个二次函数却能完美分割,这就是核函数的意义。本文所使用的核函数是高斯核函数:
论文中将核函数引入样本的点积,即:
5.2 核函数与循环矩阵的结合
对于任何的循环矩阵 X,还是以一维的原矩阵 x 为例,可知:
其中由于 P 是循环矩阵的基础变换矩阵,也就是前面所提到的 K 矩阵,这里是为了与核函数区分开来,在矩阵点积中,两个矩阵的元素对应相乘,因此两个矩阵同时移位$ P^i$,并不会影响结果。
由公式(5-3)可知,只要行号和列号的差值相同,其对应元素的值就相同,所以 $K^{xx}$是循环矩阵。再利用循环矩阵的特性(2-3)可得:
同理可得:
虽然原论文关于w的推导错误了,但是代码是根据$\alpha $来实现的,所以正确。
5.3 不同核函数的计算
从最基础的内积出发,其核函数形式就是:
对于多项式核,则有:
对于 RBF 径向基核,也就是常说的高斯核函数,有:
6. 模板图像的获取
模板图像是基于第一帧图像目标框所得到的,其具体获取过程如下:
Step1 保持初始目标框中心不变,将目标框的宽和高同时扩大相同倍数(论文中取 2.5 倍);
Step2 设定模板图像尺寸为 96,计算扩展框与模板图像尺寸的比例:
Step3 然后将 scale 同时应用于宽和高,获取图像提取区域:
Step4 由于后面提取 hog 特征时会以 cell 单元的形式提取,另外由于需要将频域直流分量移动到图像中心,因此需保证图像大小为 cell大小的偶数倍,另外,在 hog 特征的降维的过程中是忽略边界 cell 的,所以还要再加上两倍的 cell 大小:
Step5 由于 roi 区域可能会超出原图像边界,因此超出边界的部分填充为原图像边界的像素;
Step6 最后利用线性插值的方式将 roi 区域采样为 template 大小。
7.特征提取
7.1 f-hog特征
hog 特征又叫做方向梯度直方图,顾名思义,它所描述的是图像各像素点的方向梯度它对图像几何的和光学的形变都能保持很好的不变性。而论文中所用的hog 特征与常规的不同,具体的不同和实施细节我会在下文详细介绍:
Step1 梯度幅值计算。
计算模板图像 RGB 三通道每个像素点的水平梯度 dx 和垂直梯度 dy,并计算各点的梯度幅值,以最大的梯度幅值所在通道为准:
Step2 梯度方向判定。
如果像素点最大幅值所在通道为 m,则利用该通道的水平梯度和垂直梯度计算该点的梯度方向,论文中将[0,180)分为了 9 个方向,同时还将[0,360)分为了18 个方向,具体方向归属则是利用该像素点梯度在模板方向上的投影值确定:
分别通过以[0,180 ) 和[0,360 )为周期将个像素点的方向投影至这两个区间,从而每个像素点都有两种方向;
Step3 cell的分割。
确定 cell 单元尺寸(论文中设为 4),因此,水平方向有 sizeX=24,竖直方向也有 sizeY =24 个 cell,由于在计算像素点梯度时,边界像素点的梯度都是通过镜像幅值边界像素的方式计算的,因此论文中并未考虑边界点的梯度。每个 cell中的方向梯度直方图应该有 9+18 = 27 个方向。
Step4 cell 内像素点梯度幅值加权方式。
论文代码中关于 cell 的方向梯度直方图的求解很特别。对于每个 cell,根据其尺寸,设计了两个离散序列,因为比较有规律,所以当做两个函数 x 和 y:
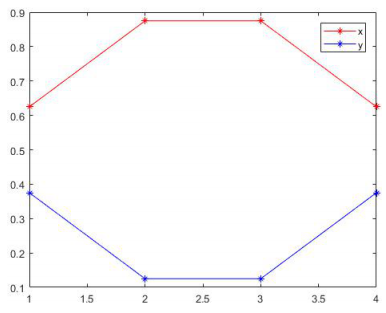
通过图像可以看到,随着 cell 内像素点横纵坐标的偏移,对应的点的 x,y 值一直在变化,且两个函数关于 0.5 对称,另外 x+y=1,利用这一特性,可以利用x 和 y 进行组合分解:
利用公式(7-3),论文代码中将每个 cell 等分为 4 部分(左上、右上、左下和右下),每一部分都是由包含该 cell 在内的相邻 4 个 cell 的同一部分加权平均得来的,其权重即为公式(7-3)所示的四个部分。具体组合方式如下(以 cell左上角部分为例):

可以发现,cell 左上部分的加权方式是以自身为左上角,然后取相邻的其他三个 cell 的左上部分组成一个新的虚 拟 cell,再利用上图 所示的权重分布将四个cell 的左上部分进行加权平均,权重正是 $x^2$,xy,yx,$y^2$。同理,cell 的其他三个部分也是一样的原理,比如 cell 的右下部分,则是将该 cell 的右下部分作为虚拟 cell的右下角,然后分别取该 cell 左上,正上,正左三个方向相邻的 cell 的右下部分组成新的虚拟 cell,再进行加权平均。
当然,对于边界 cell,则只选取不超过边界的部分 cell 进行不完整加权。Step5 方向梯度直方图计算。
对于 cell 内每个像素点,将其梯度幅值分别以[0,180 )和[0,360 ) 两种投影区间累加至对应梯度方向直方图中,在按照上一步中提到的加权方式计算完 cell特征之后,每个 cell 保留了 9+18 个方向的梯度。
Step6 相对领域归一化及截断。
对于每个 cell,分别取包含其在内的相邻四个 cell,如下图所示(好丑-_-||,为了区分四个 cell 的不同,尽力了。。。)
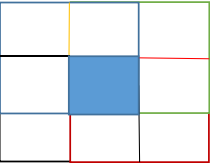
因此有四个组合方式,每种组合方式都取该组合方式内四个 cell 的方向梯度直方图的前 9 个方向梯度的 L2 范数 val,然后用该 cell 内 27 个方向的梯度直方图除以 val,即可得到规范化之后的 hog 特征。四个组合可以得到四组 hog 特征,即 9+9+9+9+18+18+18+18=108 个方向。
可以发现边界 cell 无法得到这么多方向,因此去掉边界 cell。所以sizeX=24-2=22,sizeY=22。
Step7 PCA降维。
作者从大量各种分辨率的图片中收集了很多36维特征(按照之前的定义),并且在这些特征上进行了PCA分析,发现了了一个现象:由前11个主特征向量定义的线性子空间基本包含了hog特征的所有信息。并且用降维之后的特征在他们的任务(目标检测)中取得了和用36维特征一样的结果。

如果用 $C_{ij}$表示第 i 组 hog 特征的第 j 个方向,则原作者代码中的降维方式分别如下:
然后将两种降维方式得到的特征进行组合,得到 27+4=31 组特征。
原论文流程示意图如下:
7.2 CN/CN2特征
该颜色特征将颜色空间划分为了黑、蓝、棕、灰、绿、橙、粉、紫、红、白和黄共11种,然后将其投影至10维子空间的标准正交基上,这里作者给出了32768种颜色向量组合。再利用PCA技术,采用奇异值分解方式提取其中主要的两个颜色作为最终的特征。由于CN2特征是单目标跟踪领域中很有效的一种人工特征,这里对其原理做出详细描述:
Step1 根据如下计算公式,作者给出了模板矩阵w2c(32768×10):
将原图的RGB三通道数据带入其中,图中每个像素位置都能得到一个索引号,范围是1~32768,将此索引号带入w2c中,便可得到一个宽高与原图一致,通道数为10的CN矩阵x_pca,与此同时,将其形状重塑为(W×H)×10的二维矩阵;
Step2 逐帧更新外观矩阵:
Step3 开始PCA,先按列对矩阵去中心化,并计算协方差矩阵cov(10×10):
Step4 进行奇异值分解,由于对于任何矩阵$A \in {R^{m \times n}}$都可以利用奇异值分解为$A = UD{V^H}$, 其中$U \in {R^{m \times m}}$,$D \in {R^{m \times n}}$,$V \in {R^{n \times n}}$,而对于矩阵cov,U=V,那么AU=UD,所以U的列向量是协方差矩阵的特征向量,D是协方差矩阵的特征值:
Step5 取U的前2列特征向量,逆分解得到新的协方差矩阵:
Step6 更新协方差矩阵:
Step7 得到CN2特征:
下图可以看见原图,灰度图以及CN2特征图的区别,因为CN特征有10个通道,这里我就不放了:
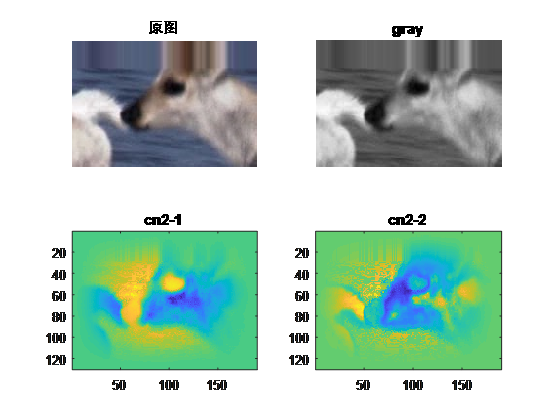
8. 算法实现
8.1 多通道图像特征矩阵求解
利用上述理论推导可以求得每一帧 fhog 特征,如果将其视为多通道的话,那么就是 31 通道的图像特征矩阵,然后分别对各通道使用二维汉宁窗进行滤波,为了降低 FFT 过程带来的频谱泄露,其函数形式如下:
然后分别对各个通道求解其,对各通道数据进行多通道处理,处理方式如下:
8.2 标签制作
利用第五章所得结论,可以求得${\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}}
\over \alpha } }$。对于 groundtruth,由于模板函数的中心就是目标框的中心,因此论文中使用高斯分布函数作为标签,其分布函数如下:
其中,(cx,cy)表示图像特征矩阵中心,padding 表示扩展框相对目标框的变化比例 2.5,${output_\sigma }$表示设定的一个值 0.125。
8.3 多尺度检测
论文代码中,作者设置了三种尺度,设定尺度步长为 scalestep=1.05,然后分别以 $1.05^{-1}$,$1.05^0$,$1.05^1$三种尺度 scale 进行检测,这里尺度的操作对象是第六章所提到的 roi 矩阵,即。首先,为了防止在更新过程中目标框左上角位于图像边界,从而目标框变成了一条线或者一个点,作者将这一类目标框的左上角向远离图像边界的方向移动了一个单位。
每一尺度都能求得 f(z)响应矩阵,虽然该响应矩阵对应了循环矩阵每个块矩阵的响应,但是第 i 行第 j 列的块矩阵所对应的响应,正是目标框右移 i-1 个单位,下移 j-1 个单位后的响应,即下一帧图像矩阵 z 的响应。对于该响应矩阵,找出其最大响应值 peakvalue 和最大响应位置 $p{xy}$。
如果最大响应位置不在图像边界,那么分别比较最大响应位置两侧的响应大小,如果右侧比左侧高,或者下侧比上侧高,则分别将最大响应位置向较大的一侧移动一段距离:
然后计算此位置与图像中心的距离 res。
对于不同的尺度,都有着尺度惩罚系数 scale_weight,用此系数乘以该尺度下的最大响应值作为该尺度下的真实最大响应值,取最大响应值对应的尺度为最佳尺度,记为 best_scale。以此来更新目标框参数 T(x,y,w,h):
8.4 模板更新
首先获取原尺度下当前帧的 fhog 特征矩阵 z,作者代码中这一部分没有用汉宁窗进行滤波,可能是考虑到更新时这一部分的权重不大,其模板和${\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}}
\over \alpha } }$ 的更新公式如下:
9.总结
整体来讲,本文通过循环矩阵的方式将循环移位的运算复杂度降低了,然后通过引入傅里叶变换使得主要的矩阵乘法变成了点乘,再次降低了运算量。再通过引入对偶空间和核函数,增加了岭回归分类器的性能。整体来说,其算法结构比较简单,也正因如此,其跟踪速度也很快。
不过其中也暴露了很多问题:
- 虽然模板和 ${\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\frown$}}
\over \alpha } }$更新部分对于当前帧的权重比较小,但是其更新是针对整个矩阵进行的,所以如果出现一段遮挡的场景,此模板将一去不复返。这与 siam-fc的模板更新不同,深度网络的跟踪方式通常只是更新目标框的中心位置,以及对目标框大小的微调; - 论文中使用了三个尺度,对于尺度的应用很微小,所以作用很小,在后面Martin Danelljan 所提出的改进算法 DSST 中算法效果有显著提高,不过用了33 个尺度,其对应的算法速度也就降下来了,所以该算法的核心竞争力降低了;
- 当目标出现形变时,效果会变得很不好,因为 KCF 的核心其实是模板匹配,目标变形时,自然也就难以匹配好;
- 论文中加入的汉宁窗虽然有减少 FFT 频谱泄露的作用,但是由于其分布特性,使得边缘像素cell 的值几乎为 0,因此丢失了大量信息。可能最大响应位置并非最大,甚至有可能过滤掉出现在边缘的目标;
参考资料
High-Speed Tracking with Kernelized Correlation Filters, Joao F.Henriques, IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE , 2015.
Forsyth D . Object Detection with Discriminatively Trained Part-Based Models[J]. 2014.
原作者C++源码:https://github.com/joaofaro/KCFcpp
QiangWang复现C++源码:https://github.com/foolwood/KCF
原作者博士论文:http://www.robots.ox.ac.uk/~joao/publications/henriques_phd.pdf

