前言
最近基于深度学习的多目标跟踪算法越来越多,有用于特征提取的,有改进单目标跟踪器的,也有提升数据关联的。如果真的要总结的话那就太多了,所以我准备分类别进行介绍,这次是这一系列最后一篇。我主要介绍基于行人重识别(ReID)算法的方法,相关MOT的基础知识可以去我的专栏查看。
1.ReID与MOT的联系
在MOT任务中,一般常用的特征模型有运动模型和表观模型,其中表观模型以行人重识别(ReID)类算法为主流。Re-ID任务主要解决的是跨摄像头场景下行人的识别与检索,其中存在给定了身份的图片序列query,需要为不同摄像头场景下的多组图片gallery的行人身份进行判定。

随着现在视觉任务需求的增加,车辆重识别任务也随之诞生,包括与之对应的数据集。对于多目标跟踪任务而言,由于目前只有行人和车辆的标注,所以基本只针对这两类目标,不过最近出来一个833类的多目标跟踪数据集TAO。以行人为例,多目标跟踪相对于Re-ID多出了空间位置信息和时间联系,其更多的是针对的同一摄像头场景,还包括可能出现的相机运动。除此之外,对于Re-ID任务而言,其不需要考虑新身份的诞生和旧身份的消失,所有目标在query中一般都有对应的身份,而MOT任务中需要判定是否有可能不存在现有跟踪轨迹中,是否需要与已经丢失跟踪轨迹身份进行匹配等等,二者的异同总结如下:
| 指标 | Re-ID | MOT |
|---|---|---|
| 研究对象 | 行人/车辆 | 行人/车辆 |
| 场景 | 跨摄像头 | 单一摄像头 |
| 先验信息 | 表观信息 | 时空运动信息、表观信息 |
| 研究任务 | 行人匹配 | 数据关联 |
| 目标序列是否严格对称 | 是 | 否 |
其中,目标序列严格对称的意思是指的待比对的两个序列中,目标的id是否一致,如果不一致,则表明两个序列各自可能存在新的目标。
借鉴这个问题里面的回答行人重识别(re-ID)与跟踪(tracking)有什么区别
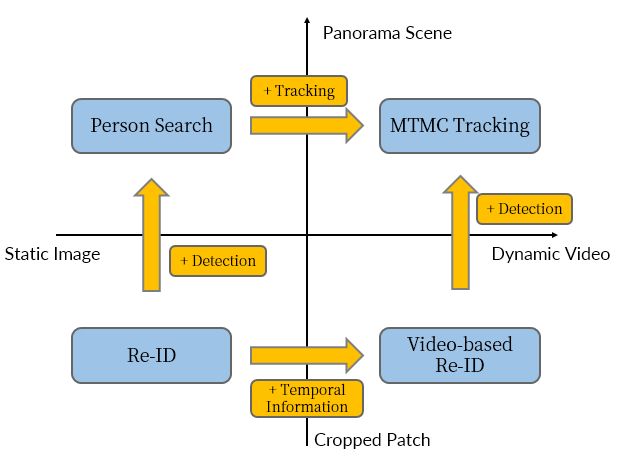
我们可以看到ReID是一个相对底层的任务,随着检测、时序信息的加入,就可以拓展至行人检索和视频ReID任务,再引入MOT则可以得到更为高层的任务MTMC(跨摄像头多目标跟踪)。实际上ReID只是个任务名,我们不要将其具象化成了某一类数据集或者某一类深度框架,我们甚至可以直接用传统的图像特征来应用于这个任务,关键要看这个任务的定义。
2.MOT/MTMC中的ReID框架设计
2.1 DeepCC
论文题目: Features for multi-target multi-camera tracking and re-identification
作者:Ergys Ristani,Carlo Tomasi
备注信息:CVPR2018
考虑到MOT和MTMC在表征模型方面的相似性,我们一并介绍。DeepCC是MTMC领域的一篇经典论文,我们可以先看看MTMC的基础流程:
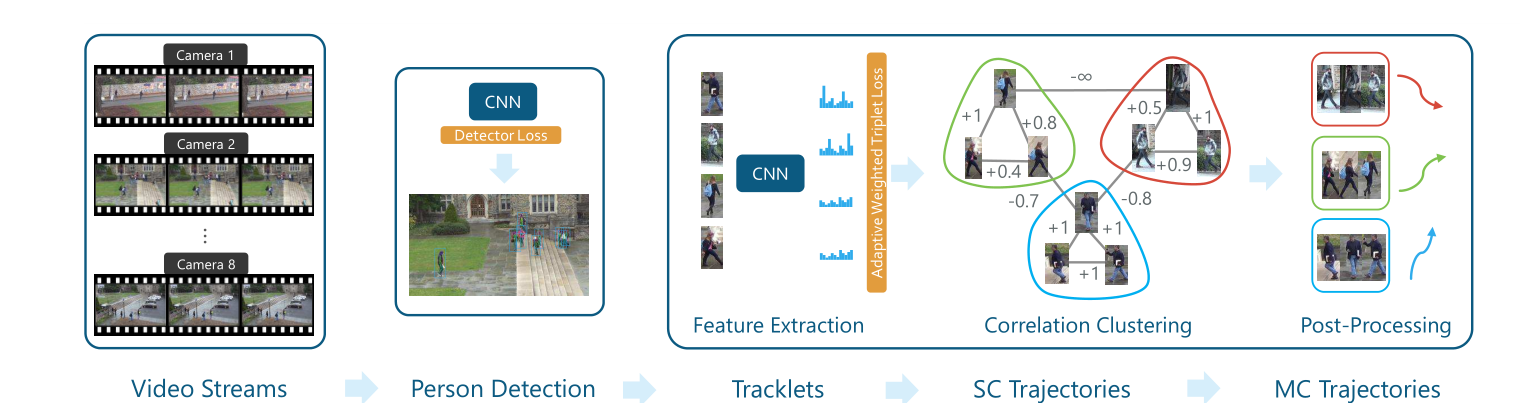
给定多个摄像头的视频流,由检测器得到所有的观测行人信息,通过提取每个人的特征对每个行人进行关联匹配/聚类,最后通过后处理进行完善。这篇论文主要做的是ReID任务在MTMC任务上的适配,其关注点不在网络的设计上,而是从训练策略上着手。首先我们不妨思考下如果从MTMC/MOT任务中抽象出ReID任务,无非就是数据集的提取(即相同身份行人序列的抽取),网络框架的设计(特征模型),还有训练策略(损失函数的设计等),而且这里面抽取出来的行人序列在多样性等方面可能都与ReID数据集有着差异。当然,不同视频数据集之间的域自适应性问题是这几个任务的共性问题。
由于我们这次主要关注的是表观特征层面,所以对于其他的部分就暂时忽略。DeepCC设计了一种自适应的三元组损失函数:
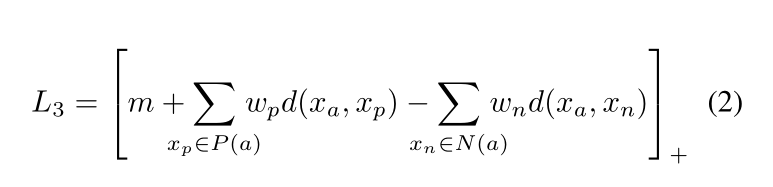
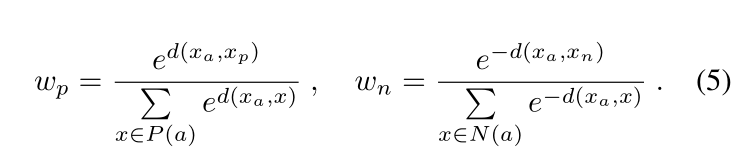
我们知道的是,在batch-hard triplet loss,选取的是相同身份中距离最远的样本组为positive,不同身份中距离最近的为negative组。作者并没有使用batch-hard的方式,通过自适应权重的设计我们可以看到,作者通过softmax的方式,使得相同身份样本组中距离越大的权重越大,不同身份样本组中距离越小的权重越大,相当于给了easy sampels更多的注意力。
为了防止数据量大了之后,很多batch不存在hard samples,作者创建了两个样本池:

根据给定的query,设计一组难例样本池和一组随机身份样本池,在训练的时候就可保证难例样本对的正常获取。
很可惜,由于国外对于个人隐私的保护,MTMC相关的数据集都被禁用了。
2.2 NOTA
论文题目:Aggregate Tracklet Appearance Features for Multi-Object Tracking
作者:Long Chen , Haizhou Ai, Senior Member, IEEE,RuiChen , and Zijie Zhuang
备注信息:SPL2019
如果说DeepCC关注的是ReID任务在MTMC任务中的训练策略设计,那NOTA就是针对ReID任务在MOT任务中的网络框架设计。熟悉MOT任务的人应该知道,由于不同质量观测信息和遮挡等问题的影响,我们直接根据给定行人框提取的行人特征并不一定可靠,例如下图中,一个行人框中可能存在多个行人和大量背景信息。
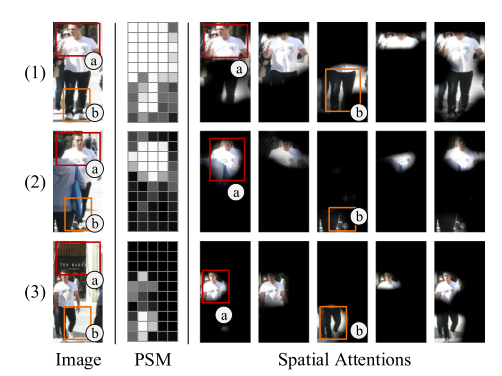
因此这篇文章设计了一种时空注意力网络,其中空间注意力模型叫做Position-Sensitive Mask,类似于检测框架中的R-FCN算法,通过将空间分为3x3的网格,每个网格都预测前景/背景的概率,整体打分取平均得到这张图属于前景的概率。
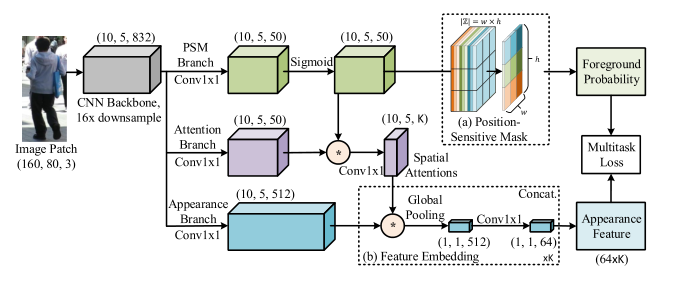
紧接着,利用前景背景预测分支的mask对预测的注意力mask进行element-wise乘法,相当于一次过滤,从而得到空间注意力,再对表观特征进行一次element-wise乘法。那么时间注意力来自哪里呢?
作者所针对的是测试阶段的跟踪序列,以前景背景mask作为时间注意力,然后对跟踪序列每个patch的特征和前景背景mask进行加权融合得到轨迹特征,用于轨迹相似度计算:
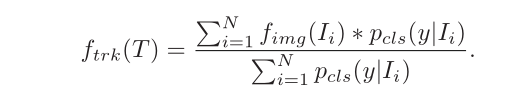
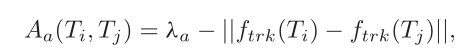
而关于特征模型,这篇论文做了很多实验,挺有价值的:
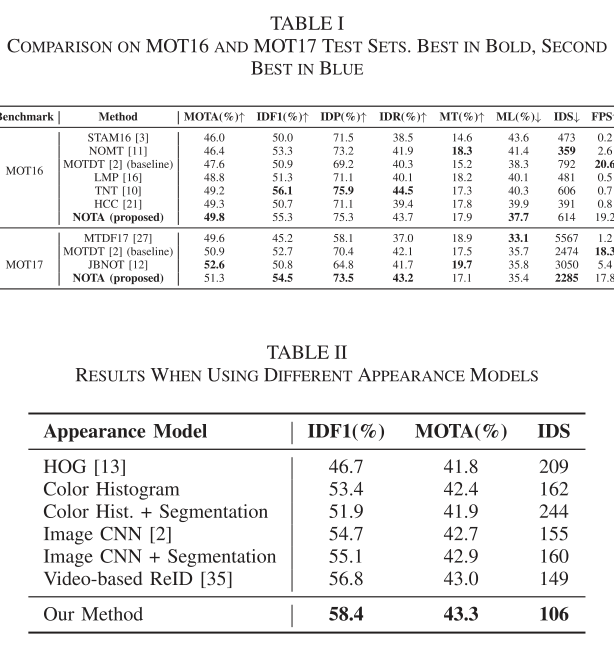
2.3 LAAM
论文题目:Locality Aware Appearance Metric for Multi-Target Multi-Camera Tracking
作者:Yunzhong Hou, Liang Zheng, Zhongdao Wang, Shengjin Wang
备注信息:CVPR2019 WorkShop
LAAM这篇关注的主要是ReID任务在MTMC任务中的数据集构建和训练策略,这里有作者的详细讲解,我也相应地谈谈。我们知道无论是Tracktor++[4]还是DeepSort[5],二者都是单独训练的ReID特征模型,然后直接应用于MOT任务。LAAM一文就是提出了一个re-ID特征是否适合直接用于跟踪任务的问题。
作者提到:
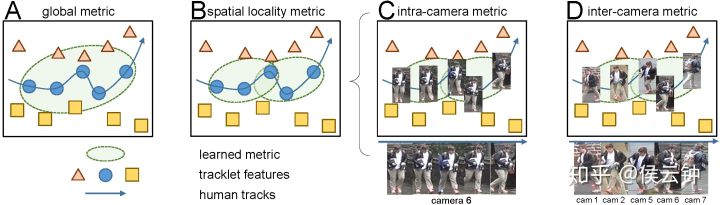
由于目标(行人/车辆)轨迹(trajectory)的连续性,在一般情况下,跟踪系统只需要匹配一个局部邻域中的目标,而不需要全局匹配。
- 局部邻域:对于单相机跟踪,指代同相机的连续帧内的样本;对于跨相机跟踪,指代相邻(距离较小)的几个相机(如下图小框中的一组相机)内的样本。
- 全局:指代全部相机中的样本。
跟踪系统中的匹配一般被限制在局部邻域内,而应用于相似度估计的重识别特征,则是从全局学到的,相似度估计的结果直接决定数据匹配的性能。在这个关键部分,出现了局部vs全局的失配,则会对系统整体性能有很大影响。
的确,在MTMC任务中,如果处理的是较短时间内的连续视频帧,目标更倾向于出现在较小的局部空间内,并且特征差异性并没有很大。
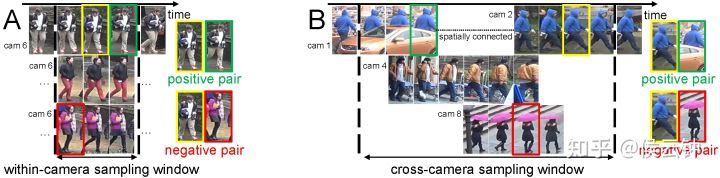
对此作者就提出对相机内和相机之间的样本分开训练,即同相机内的正负样本来自于同一相机,不同相机内的正负样本来自于不同相机。
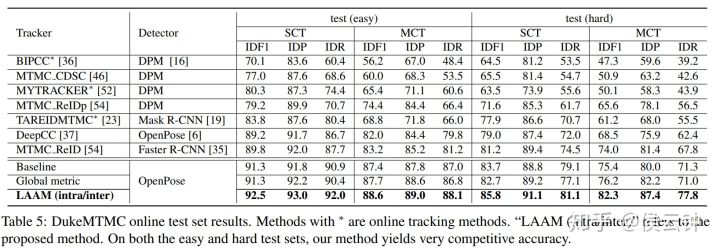
虽然方法很简单,但是也具有一定启发意义:
2.4 STRN
论文题目:Spatial-temporal relation networks for multi-object tracking
作者:Jiarui Xu, Yue Cao, Zheng Zhang, Han Hu
备注信息:ICCV2019
在MOT任务中,除了表观特征,还存在运动特征,除此之外,跟踪序列与跟踪序列/目标之间的相似度度量也是一个问题。STRN这篇论文所针对的就是运动表观特征的结合、跟踪序列特征的融合和目标与周围目标间的交互。下图中虽然t帧中中心目标被遮挡了,但是其周围目标还在,所以依旧被跟踪到了,这一点对于遮挡问题有一定缓解能力。
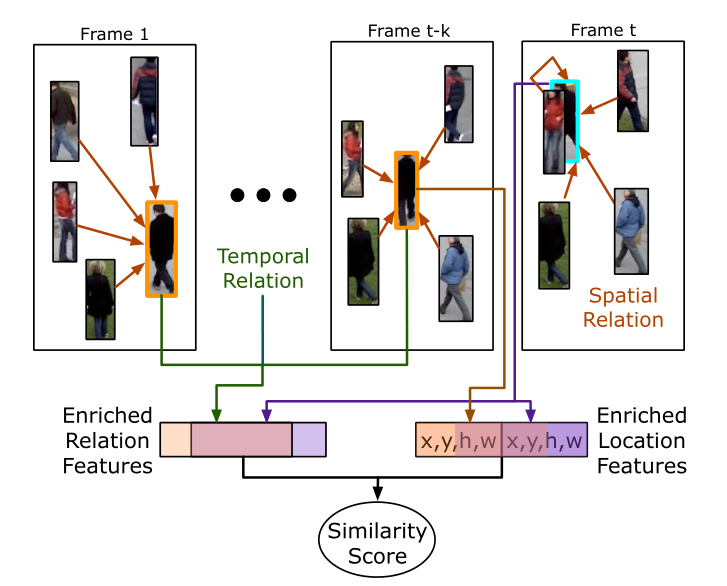
首先,作者利用周围目标表观特征对中心目标的特征进行更新:
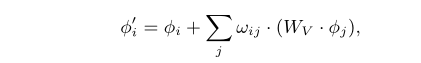

其中周围目标的注意力模型(ORM)权重是通过一组仿射矩阵求得周围目标与中心目标的相似度和位置形状相似度加权得到的。

而对于时间信息,同样地,就是对于跟踪序列中不同特征的注意力打分:
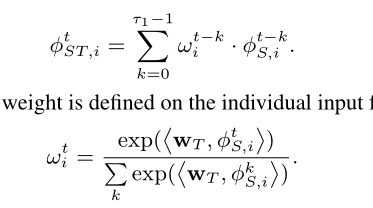

接下来,作者对于每条跟踪序列和每个观测行人之间的相似度度量进行了研究,首先是将跟踪序列最新的一部分特征加权融合,再与待比对特征进行拼接,通过一个线性转换得到表观关联性特征。
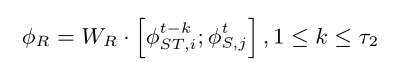
同样地,计算出二者的余弦距离:
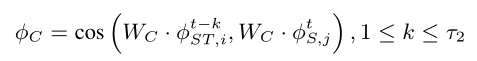
那么对于位置信息L和运动信息M则有:

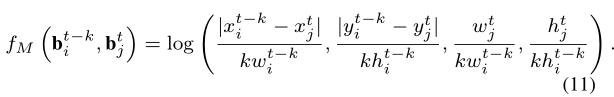
我们可以看到的是,这里面大多数的相似性度量都是人为设定的,但是也都引入了线性变换矩阵W,这些都是通过一个小网络得来的:
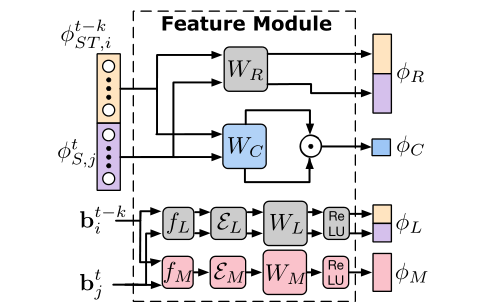
整体框架如下:
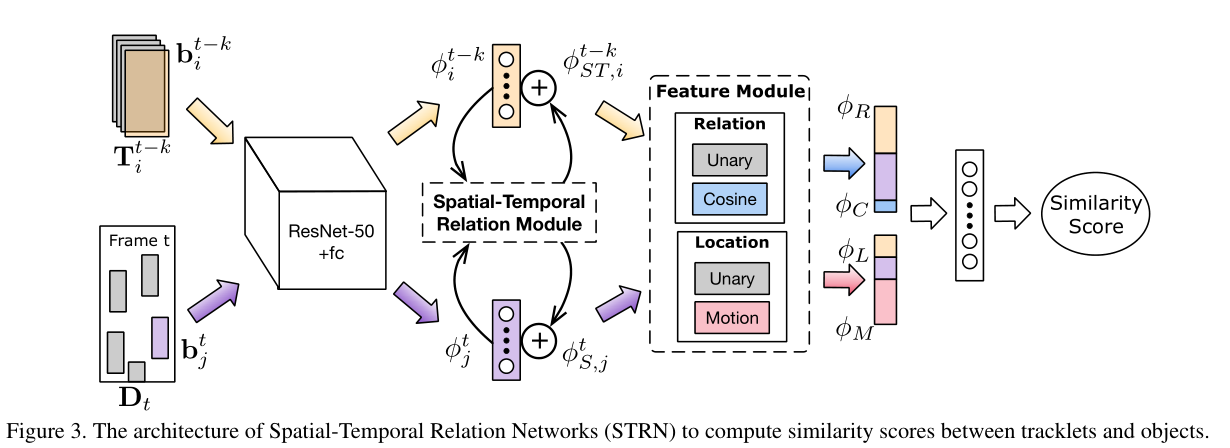
其效果如下:
3 总结
这次我主要介绍了ReID和MOT/MTMC等跟踪人物的结合,可以看到ReID任务可以应用于跟踪人物中的表观特征模型部分。而应用时则需要注意数据集构建的差异、网络框架的设计、训练策略的问题、ReID中域自适应性问题、特征融合与选择等问题。随着这两年联合检测和跟踪的框架的兴起,在这类集成框架中引入ReID分支的算法也相继出现,包括JDE和FairMOT等。那么单独使用ReID特征进行跟踪的话效果会如何呢?各位不妨试试。
参考文献
[1] Ristani E, Tomasi C. Features for multi-target multi-camera tracking and re-identification[C]. in: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. 6036-6046.
[2] Chen L, Ai H, Chen R, et al. Aggregate Tracklet Appearance Features for Multi-Object Tracking[J]. IEEE Signal Processing Letters, 2019, 26(11): 1613-1617.
[3] Yunzhong H, Liang Z, Zhongdao W, et al. Locality Aware Appearance Metric for Multi-Target Multi-Camera Tracking[J]. arXiv preprint arXiv:1911.12037, 2019.
[4] Bergmann P, Meinhardt T, Leal-Taixe L. Tracking without bells and whistles[C]. in: Proceedings of the IEEE International Conference on Computer Vision. 2019. 941-951.
[5] Wojke N, Bewley A, Paulus D. Simple online and realtime tracking with a deep association metric[C]. in: 2017 IEEE international conference on image processing (ICIP). IEEE, 2017. 3645-3649.
[6] Xu J, Cao Y, Zhang Z, et al. Spatial-temporal relation networks for multi-object tracking[C]. in: Proceedings of the IEEE International Conference on Computer Vision. 2019. 3988-3998.
[7] Wang Z, Zheng L, Liu Y, et al. Towards Real-Time Multi-Object Tracking[J]. arXiv preprint arXiv:1909.12605, 2019.

