前言
之前的博客中我们介绍了联合检测和跟踪的多目标跟踪框架,这类框架最大优势在于可以利用优秀的检测器平衡不同观测输入的质量。随之又介绍了端到端的数据关联类算法,这类算法的优势在于可以利用MOT数据信息缓解人工提取特征和计算特征距离的弊端。这次我们要介绍的是基于单目标跟踪(SOT)算法的MOT算法,这类算法的优缺点可以看我下面的介绍。
1.前情回顾(FAMNet、DMAN)
1.1 DMAN
论文题目:Online multi-object tracking with dual matching attention networks
备注信息:ECCV2018
DMAN算法我不小心放在了数据关联部分,这次我们简单回顾一下(具体可见上次的博客):
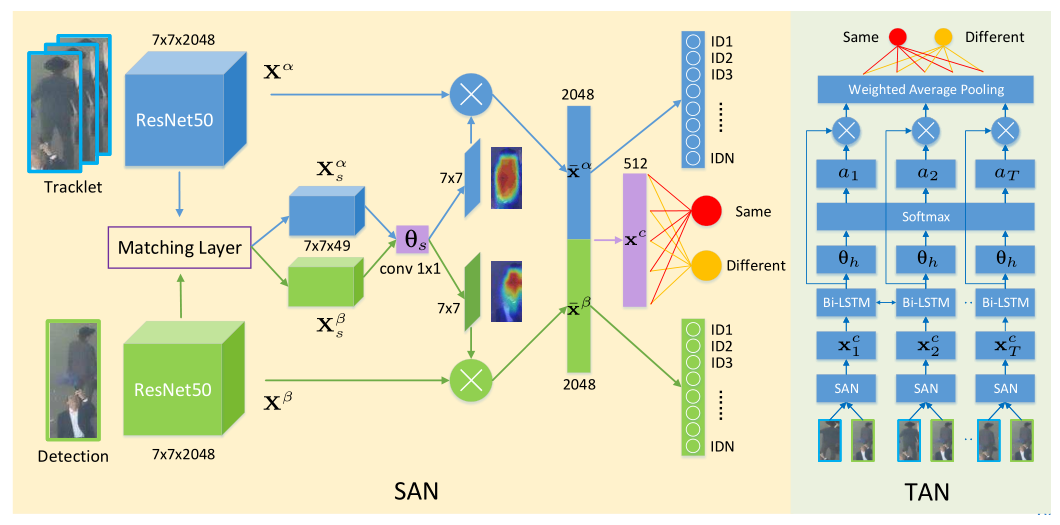
我觉得DMAN算法的主要特点在于:
- 利用Bi-LSTM网络实现了观测框与目标轨迹历史特征序列的端到端特征提取与比对;
- 将基于改进版ECO的SOT模块嵌入了网络中,其主要利用的是响应图信息,而响应图中包含有目标的定位和分类信息;
- 在数据关联部分,我们可以注意到存在两个识别部分,作者称之为时空注意力,其中时间注意力就是第一点中的verfication任务,而空间注意力就对应图中的identification任务 ,这里利用SOT输出的响应图作为注意力mask,分别基于特征预测了目标身份信息。
对于第一点,其实通过图就可以明白,是通过对于历史轨迹特征的质量进行自适应评估,并对特征自动融合。而对于第二点,关于SOT如何融入网络,可以自行搜索CFNet等SOT网络。而对于ECO算法,作者考虑到相似表观目标中容易出现的多峰问题进行了改进:
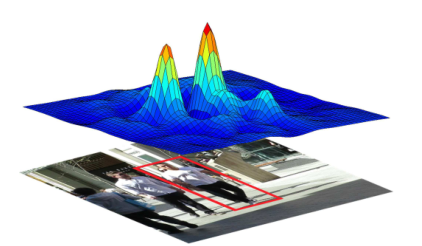
即将处于目标附近的hard samples的惩罚权重变大:
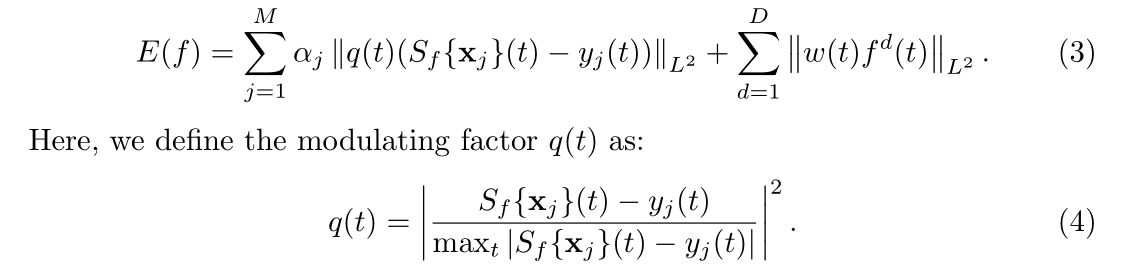
1.2FAMNet
论文题目:Joint learning of feature, affinity and multi-dimensional assignment for online multiple object tracking
备注信息:ICCV2019
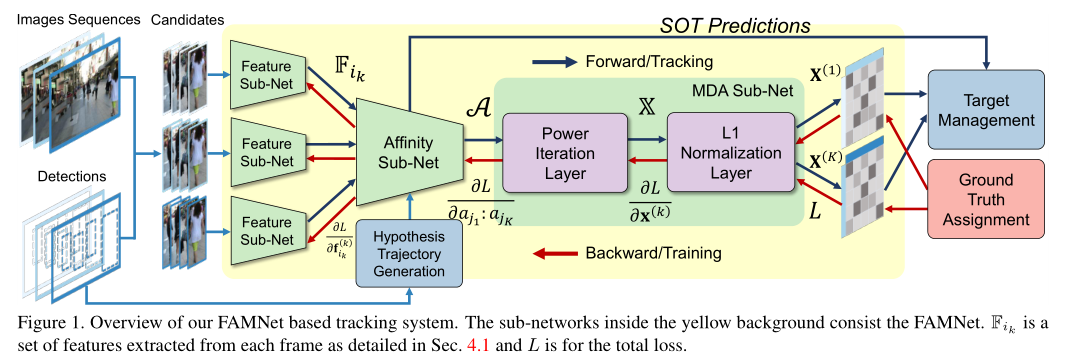
FAMNet的结构我们也介绍了,这里也总结他的特征:
- 对于相邻帧中的每个目标,利用Siamese网络进行单目标跟踪,由此隐式获取到目标的表观和位置信息,并基于响应图进行特征比对;
- 利用其提出的R1TA Power Iteration Layer降低连续多帧数据关联的复杂度,并实现连续多帧的跟踪训练。
2.STAM
论文标题:Online Multi-Object Tracking Using CNN-based Single Object Tracker with Spatial-Temporal Attention Mechanism
作者:Qi Chu,Wanli Ouyang,Hongsheng Li,Xiaogang Wang, Bin Liu,and Nenghai Yu
备注:ICCV2017
STAM算得上是一篇经典的多目标跟踪算法,而且仔细阅读之后还会发现一个亮点。其大致流程如下:
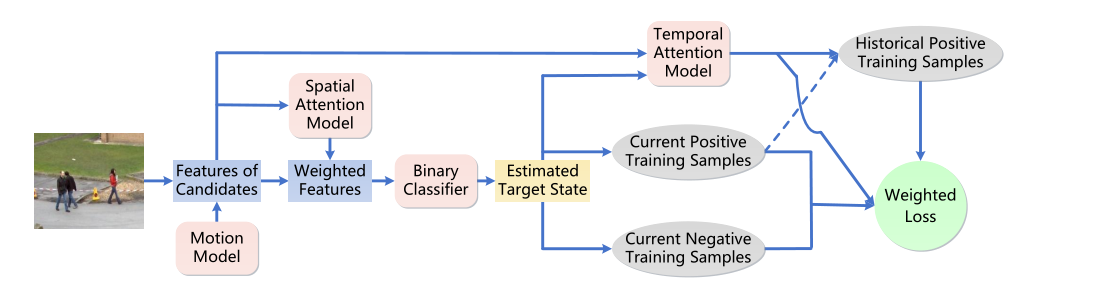
可以简单看出这里面涵盖有运动模型、目标特征提取、目标空间注意力,以及目标轨迹时间注意力等等模块。
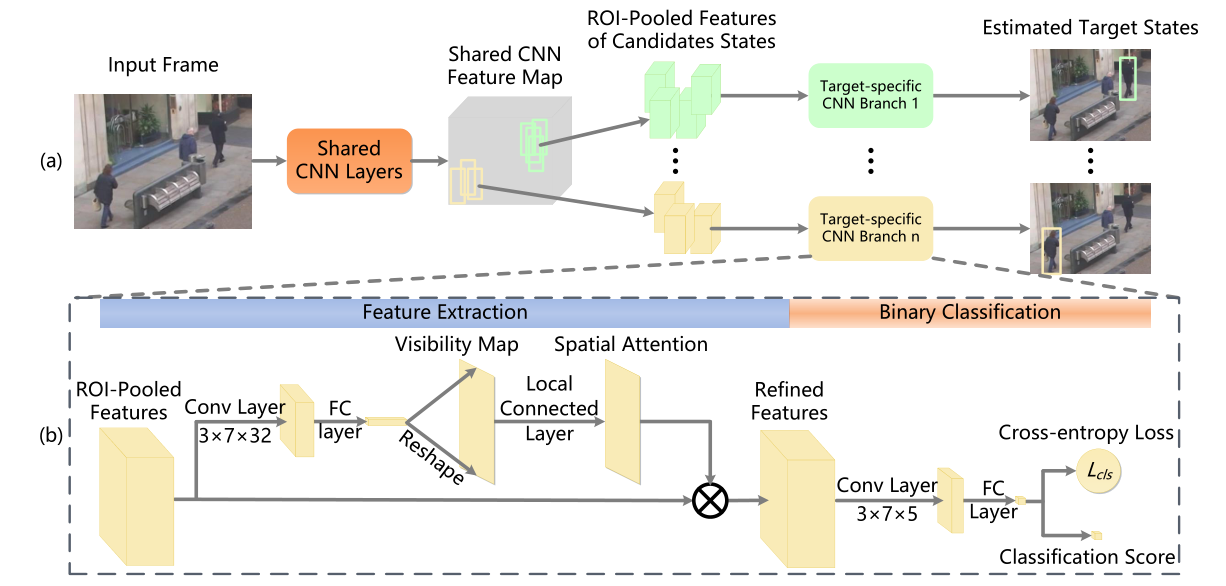
看完整个流程我惊了,尤其是ROI Pooled Features那一部分,比Tracktor++提出得还早。通过将不同目标映射到特征图上进行进一步特征提取和位置回归,只不过作者当时并没有从检测入手,所以效果不突出。
其中运动模型其实就是一个在线更新的带动量的匀速模型:
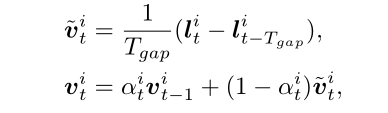
对于空间注意力,作者主要考虑了遮挡问题,通过训练可视度响应图,由此作为特征的mask,突出前景目标特征:

对于时间注意力,则是轨迹层面的质量考虑:
其通过triplet loss训练,既包含当前帧内的neg和pos,还包含历史帧的:
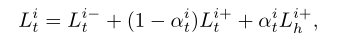
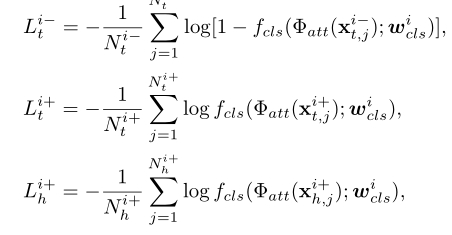
其中注意力计算如下:

对于具体的实验细节,推荐大家去看作者的博士论文《基于深度学习的视频多目标跟踪算法研究》。
3.LSST
论文标题:Multi-Object Tracking with Multiple Cues and Switcher-Aware Classification
作者:Weitao Feng,Zhihao Hu,Wei Wu,Junjie Yan,and Wanli Ouyang
LSST中作者的出发点也是针对遮挡问题:
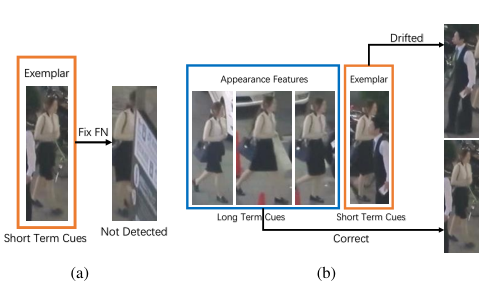
由于遮挡导致轨迹特征出现残缺,甚至身份漂移。而作者的基础跟踪器则是SiamRPN,因为快而准。。。
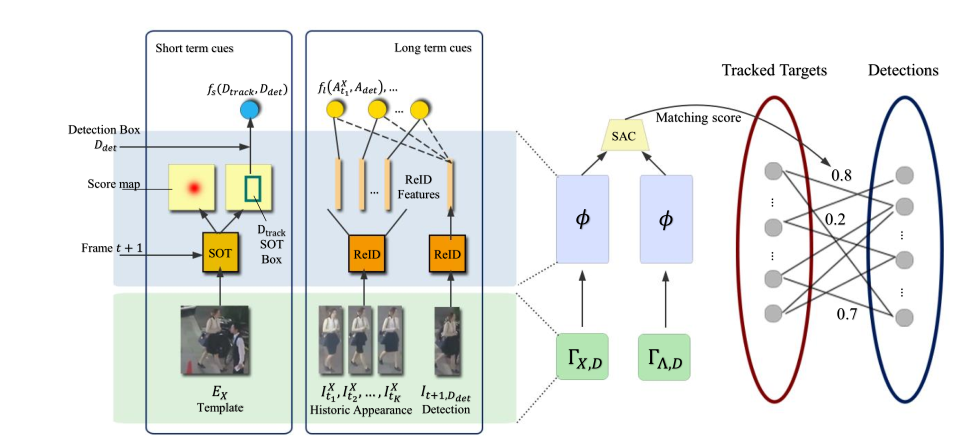
最左边就是就RPN框架的SiamRPN框架,作者称之为短期线索,这部分的质量是通过下面的公式计算的:

而对于长期线索,则自然是ReID所提取的表观信息了。作者通过ResNet18设计了一个质量评估网络,从而在目标轨迹中选择K个最好质量的特征进行比对,当然每个特征间保留了间距:
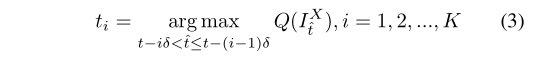
这样就得到了K组相似度,基于以上的短期和长期线索,作者利用regularized Newton boosting decision tree训练了一个分类器,由此进行数据关联。
4.KCF
论文标题:Online Multi-Object Tracking with Instance-Aware Tracker and Dynamic Model Refreshment
作者:Peng Chu, Heng Fan, Chiu C Tan, and Haibin Ling
备注:WACV2019
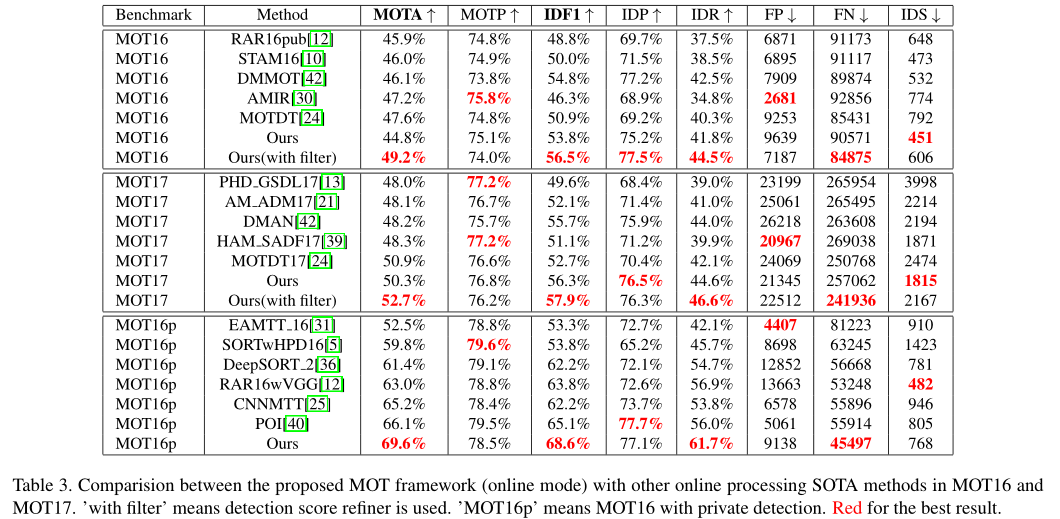
此KCF并非单目标跟踪中的核相关滤波算法,只是名字巧合罢了(论文里面没说简称,但是MOT官网写的KCF)。我们可以看到这篇论文的流程十分复杂:
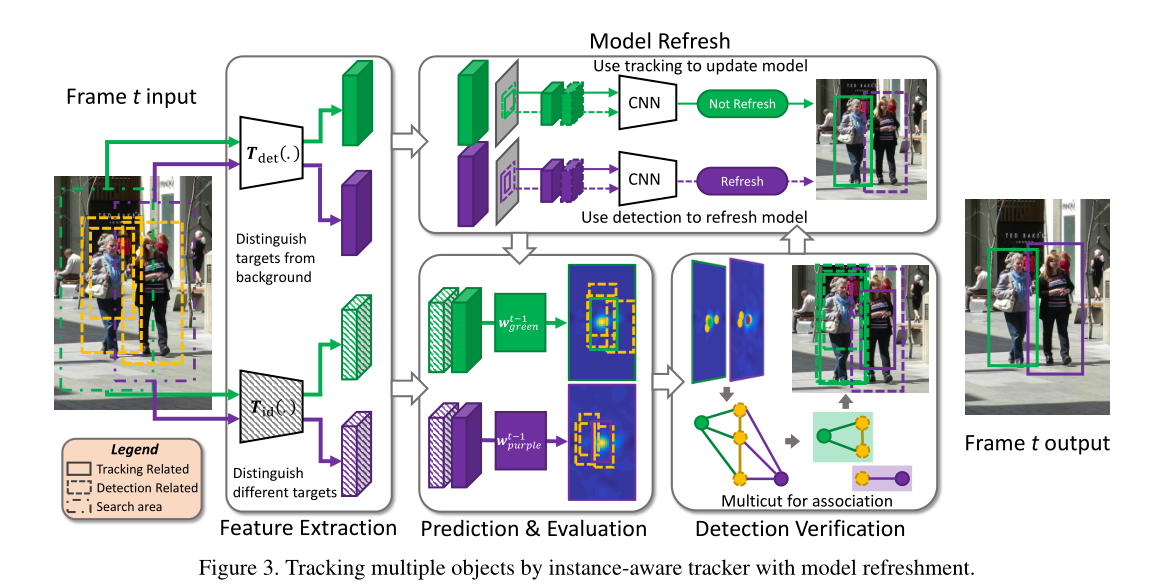
整体来看包含了:
综合前/背景相应和SOT设计Instance-aware SOT跟踪器:
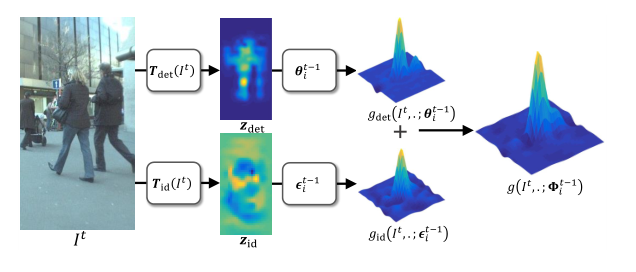
这两个响应图是直接基于岭回归算法叠加的:
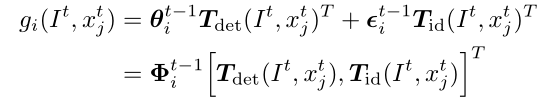
然后利用KCF的求解方式对联合模型进行求解。
基于检测的校正,即对SOT结果和Detection信息利用multicut进行数据关联,对于这类图模型的构建可以参照我之前写的博客[7]。有了目标实际上就有了图节点,那么SOT模型就是为边权而服务的:

其中X表示目标轨迹,O表示的是预测的目标位置和观测位置的集合,g就是上面的联合损失函数。即如果是相邻帧之间的边权,则用SOT中的联合损失函数值。如果是上一帧中目标间的边,则设置一个固定值。如果是当前帧节点间的边,则直接使用IOU代替。
模型更新
作者考虑到场景中可能存在的噪声信息,导致SOT跟踪结果不准,所以通过一个CNN网络判断当前SOT结果是否需要利用观测信息进行更新,如果需要,则采用观测框。
有意思的是作者采用了强化学习的策略在线训练分类器。当观测框比预测框更精准,但是没有更新,那么观测框的特征和预测框的特征会被当作positive samples。当预测框比观测框更精准,但是却更新了,那么就视为negtive samples,样本与部分训练集合并组成在线训练集进行更新。特征是通过ROI Pooling进行提取的。
当然,如果当前更新的权重并不适用于接下来的跟踪,权重还会恢复如初。
目标的管理
为了保证目标从遮挡状态恢复,作者做了一个强假设,即如果目标因遮挡而丢失,那么在出现的那一帧的数据关联中也没有与之匹配的目标。因此就可以跨帧匹配:
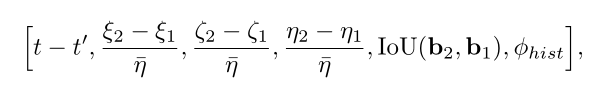
利用时间距离、位置形状、IOU、直方图等信息作为特征,通过SVM进行分类判别。
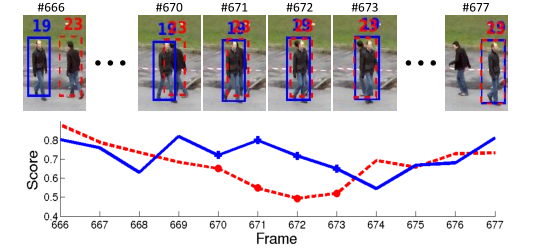
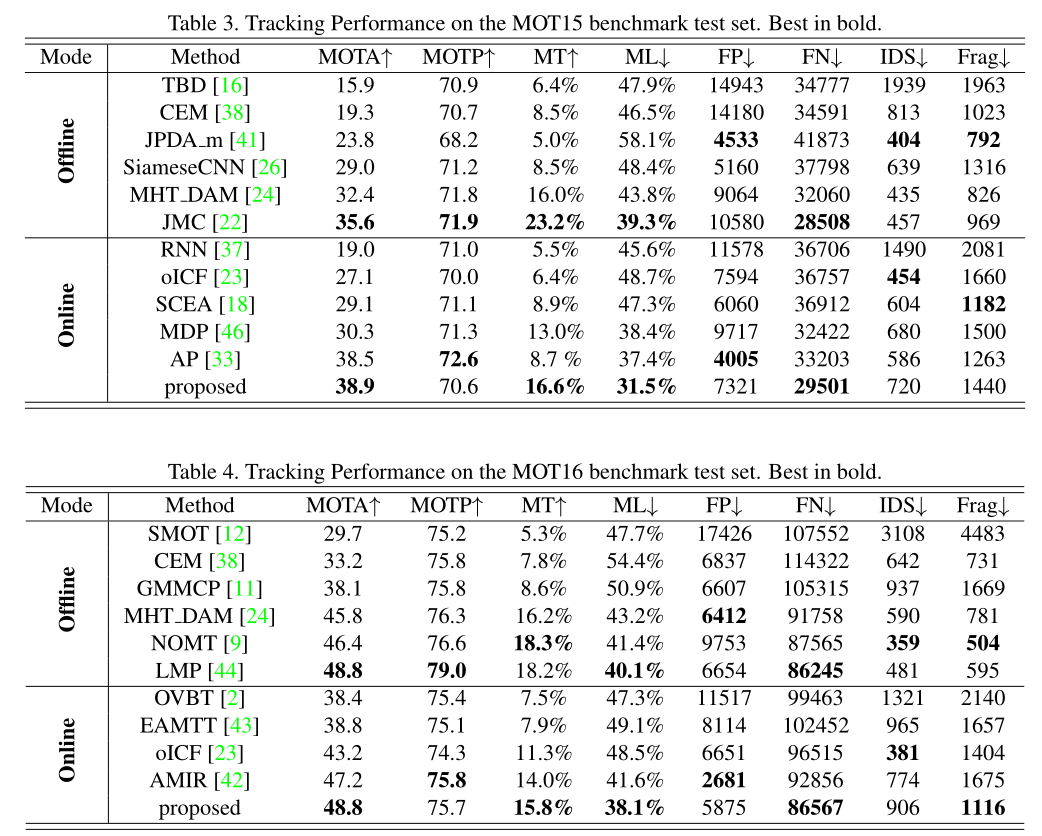
效果如下:
5.UMA
论文标题:A Unified Object Motion and Affinity Model for Online Multi-Object Tracking
作者:Junbo Yin, Wenguan Wang, Qinghao Meng, Ruigang Yang, and Jianbing Shen
备注:CVPR2020
论文链接:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2003.11291
这篇文章实际上跟前面我所介绍的DMAN算法很像,都是想利用SOT实现表观特征和运动信息的获取,进而实现在线的匹配关联:
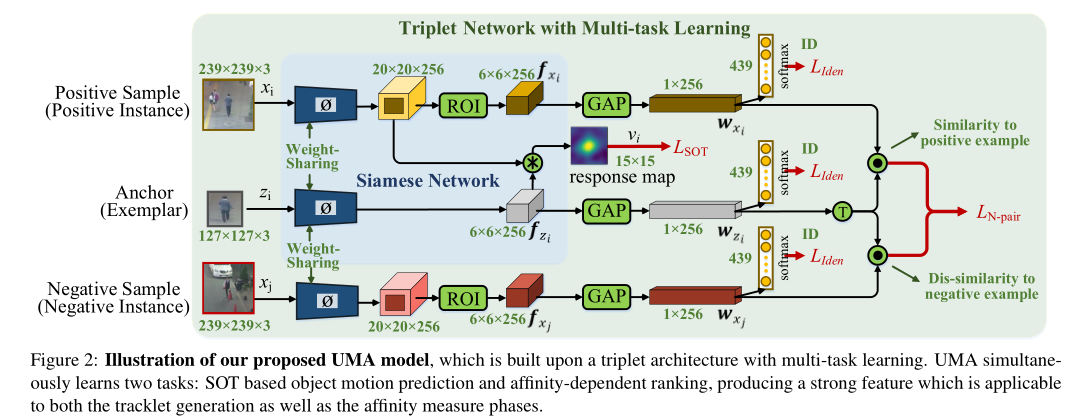
整体流程也很相似,那么UMA Tracker所基于的单目标跟踪器是SiamFC:
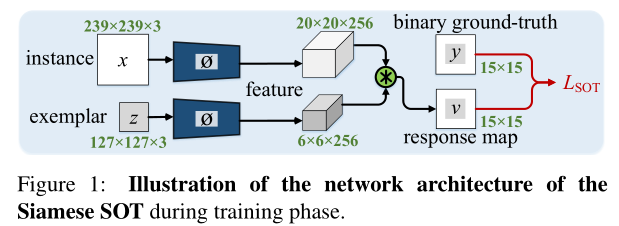
其中的特征提取都是采用的AlexNet,从图中可以看到:
- 对于正样本对则采用SOT进行跟踪比对,从而得到SOT部分的损失。
- 对于每个目标样本,还存在一个embedding模块,提取了256维的特征信息,进而进行iidentification的分类任务;
- 利用SENet的机制,实现verification任务。
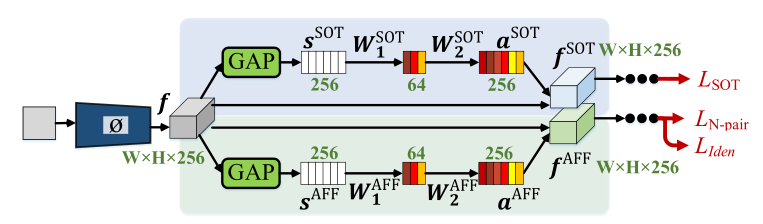
可以看到,这个整体就是基于SENet的变种,结合256个通道注意力而设计的,可以看到训练得到的特征图可视化效果还不错:

其中第2行是跟踪任务中的响应图(网络第一行分支),第3行是相似度度量任务中的响应图(网络第三行分支),所以SOT的任务跟偏向于定位和周围环境信息的提取,而Affinity部分更偏向于前景目标的部位。
对于跟踪流程,作者同样考虑了遮挡情况:
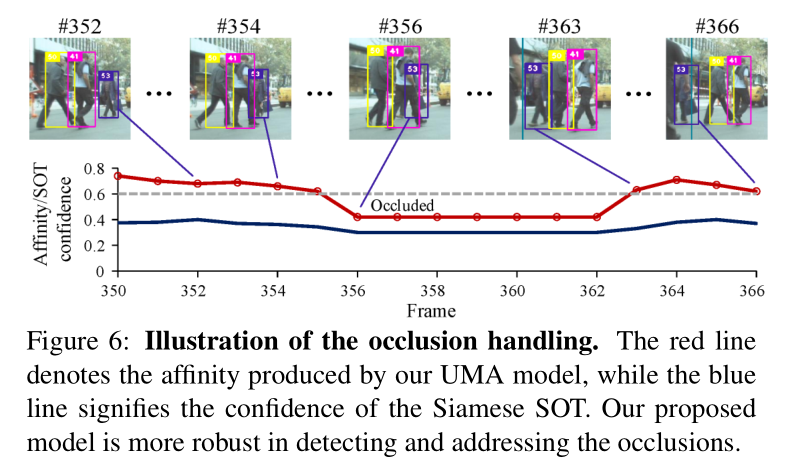
这里作者直接通过affinity相似度和IOU的变化情况估计了遮挡情况。另外,为了保证表观特征部分的信息更准确,作者利用ROI Align模块,将特征图上SOT预测出来的位置区域的目标特征单独获取出来作为表观特征的输入。
最后在数据关联部分,作者同样考虑了跟踪轨迹的历史特征,不过使用方式比较简单:
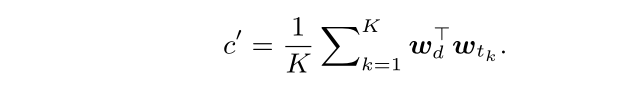
通过均匀采样,计算K组特征相似度,然后取平均作为最终的相似度。
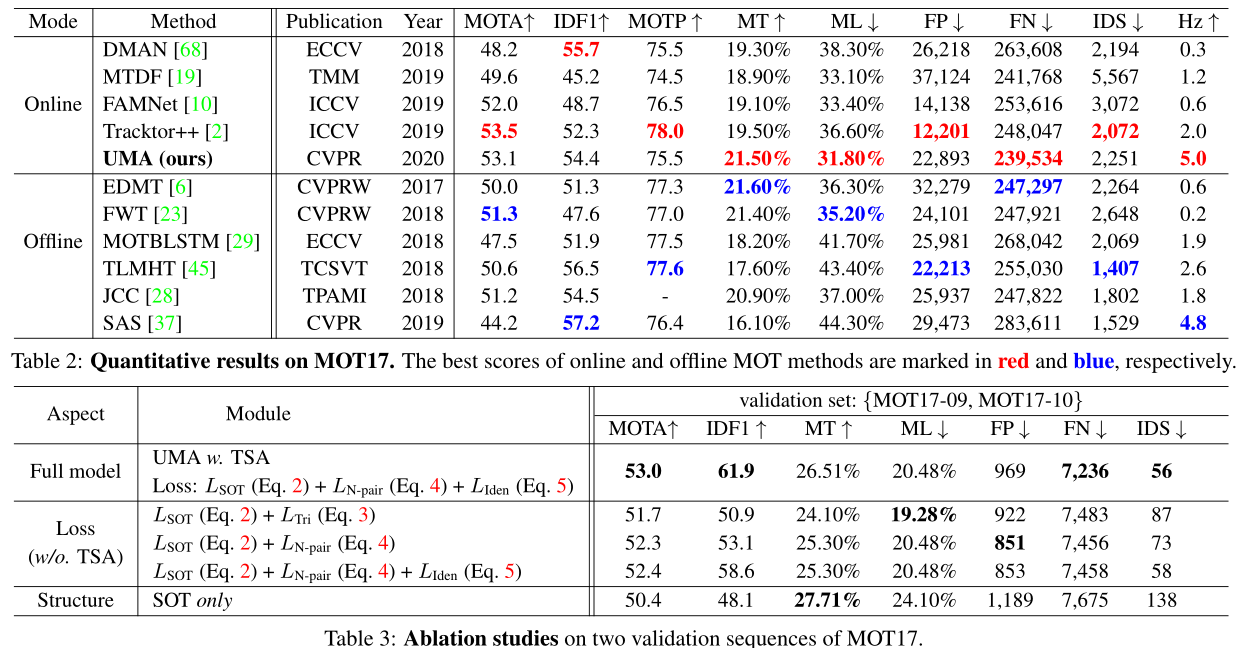
6.总结
在MOT场景中,由于Siamese结构的存在,使得SOT任务本身就自带了定位和识别等信息,所以利用SOT替代运动模型和表观模型的算法相继涌现。另外,SOT本身对于观测缺乏的问题有一定的鲁棒性,可以通过区域搜索得到暂时的目标定位信息。如果SOT本身的定位能力强,比如SiamRPN这种,甚至都相当于额外做了检测,所以基于SOT的算法理论上是可以跟基于检测的框架一较高下的。但问题在于,基于SOT的MOT目前都是针对每个目标进行一次跟踪,效率方面问题太大了,希望有后续研究可以解决这一点。
参考文献
[1]Zhu J, Yang H, Liu N, et al. Online multi-object tracking with dual matching attention networks[C]. in: Proceedings of the European Conference on Computer Vision (ECCV). 2018. 366-382.
[2]Chu P, Ling H. Famnet: Joint learning of feature, affinity and multi-dimensional assignment for online multiple object tracking[C]. in: Proceedings of the IEEE International Conference on Computer Vision. 2019. 6172-6181.
[3] Chu Q, Ouyang W, Li H, et al. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism[C]. in: Proceedings of the IEEE International Conference on Computer Vision. 2017. 4836-4845.
[4]Feng W, Hu Z, Wu W, et al. Multi-object tracking with multiple cues and switcher-aware classification[J]. arXiv preprint arXiv:1901.06129, 2019.
[5]Chu P, Fan H, Tan C C, et al. Online multi-object tracking with instance-aware tracker and dynamic model refreshment[C]. in: 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019. 161-170.
[6]Yin J, Wang W, Meng Q, et al. A Unified Object Motion and Affinity Model for Online Multi-Object Tracking[J]. arXiv preprint arXiv:2003.11291, 2020.

