前言
之前整理了C++的数据结构,但是对于python的数据结构的底层还是不大了解,这里对python中的set、list、dict、tuple等基础数据结构的原理和底层结构进行简要说明。
1.set
跟C++中的一样,python中的set也是集合的结构,,用到了散列表结构,具体结构见下文,用法类似:
1 | x = set('runoob') |
2.list
虽说叫作list,但是python中的list并不是链表,而是长度可变的动态数组,可以理解为vector:
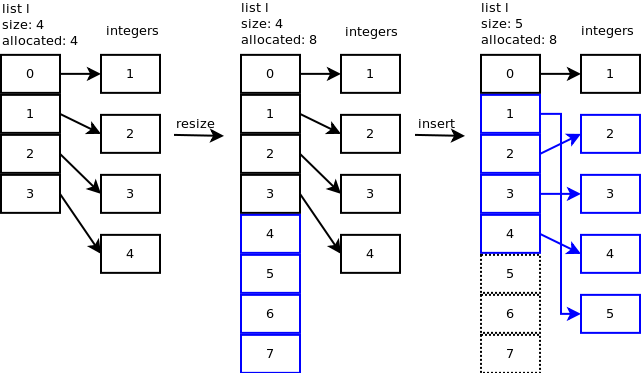
可以看到,list存储的是元素的引用,在分配空间快满的时候,会自动申请两倍空间,其效率比传统的链表低很多。
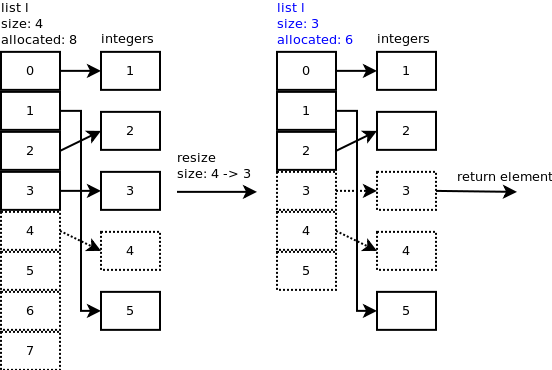
另外,当执行pop等删除操作之后,list会动态释放部分内存。
3.tuple
tuple和list很像,唯一的不同在于tuple是只读属性,但是要注意tuple的实现跟list几乎是一样,所以tuple中每个位置指向的是一个引用,引用不能变,但是引用所指向的数据可以变,比如:
1 | a=(1, 2, [1, 3]) |
4.dict
dict和set一样,都是用了哈希表来构建的,利用开放寻址法来解决哈希冲突:
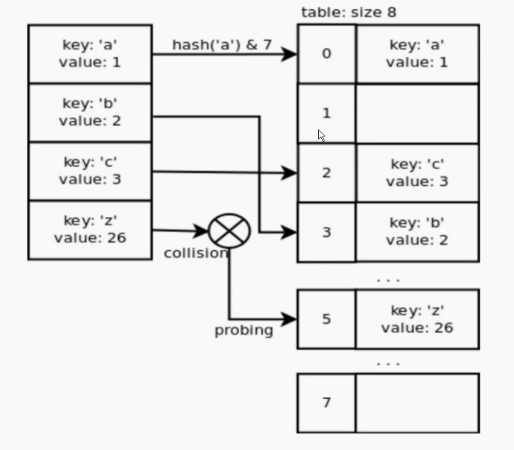
如图,在存dict的时候,首先会根据dict的key进行hash映射到对应的表元,然后再对应的表元中开辟内存,存入数据,当如果存在不同的两个key的hash结果相同的时候,就会使用散列值的另一部分来定位散列表中的另一行。
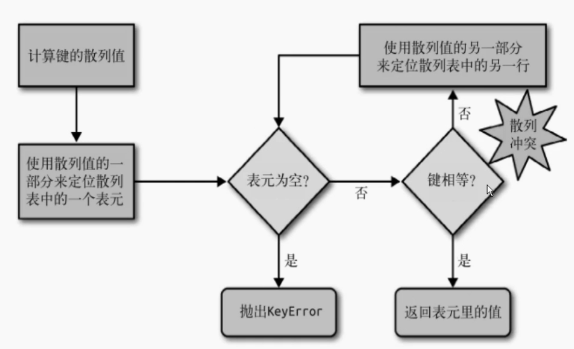
在dict中查找指定的key时,会先计算key的散列值,然后使用散列值的一部分来定位表元,如果没有找到相应的表元,则说明dict中不存在对应的key跑出KeyError异常。如果找到表元之后,会判断表元中的key是否和要查找的key相等,相等就返回对应值,如果不相等则使用其对应的散列值的其他部分来定位散列表中的其他行。(这是因为不同的对象通过的散列值有一定的概率相同,这也是为什么在存放dict时开辟内存时候需要有1/3的空地址出来,这样如果有相同的hash值就会有空的地址来存放随数据增加,还会继续开辟新的内存,以确保空内存时刻在1/3左右)
补充:①python中set的值得存储方式也是和dict一样。所以dict的key和set的值都必须是可hash(不可修改的)的对象。
②dict的花销大,因为会空出进1/3的内存主来,但是查询速度快。

