前言
C++的基础数据结构基本都存在于STL的头文件中,包括栈、队列、堆、哈希表、数组等等结构,这里我要对这些结构的基本使用做一个总结,具体包含元素的插入、查找、删除、遍历、取出等基本操作。
1.简单容器(pair/tuple)
pair和tuple属于简单的一维向量容器,二者都属于静态容器,即必须提前申明元素个数和元素类型,其中pair中只能包含两个元素,tuple个数不限。下面就二者的创建、元素访问、元素修改进行对比说明:
| pair | tuple | |
|---|---|---|
| 形式 | ||
| 头文件 | < utility > | < tuple > |
| 直接创建 | std::pair | std::tuple |
| 函数创建 | std::pair | auto bar = std::make_tuple (“test”, 3.1, 14, ‘y’); |
| 访问 | a.first和a.second | std::get<位置>(bar) |
| 修改 | a.first=x | std::get<位置>(bar)=x |
| 交换两容器 | swap(a,b)或者a.swap(b) | swap(a,b)或者a.swap(b) |
2.多功能容器(array/vector)
2.1 array
array是对数组的一种封装形式,比如:int a[] = {1,2,3,4} <=> std::array
静态数组:默认创建在栈上,元素类型和元素个数固定,要注意的是跟
tuple不同,array的元素类型只支持基础数据类型,如:int、double、char…;数组创建与初始化:
1
2
3std::array<int,5> x = {10, 20, 30, 40, 50};
std::array<int,5> y = {1,2};//剩余默认填充为0
std::array<char,5> z = {};//默认初始化为''数组属性获取:
1
2a.size()//元素数量
a.empty()//数组是否为空,eg:std::array<int,0> a;元素直接访问:
1
2
3
4
5a[0];//返回第一个元素
a.at(0);//同上
a.front();//返回第一个元素
a.back();//返回最后一个元素
a.data();//返回数组头指针迭代器访问:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16std::array<int,5> x = {10, 20, 30, 40, 50};
std::array<int,5>::iterator it;//auto it = x.begin();
for ( it = x.begin(); it != x.end(); ++it )//前向迭代
std::cout << ' ' << *it;//*iterator返回迭代器指向的元素
for ( auto it = x.rbegin(); it != x.rend(); ++it )//反向迭代
std::cout << ' ' << *it;//*iterator返回迭代器指向的元素
for ( int& p: x)//循环访问
std::cout << ' ' << p;//*iterator返回迭代器指向的元素
//防止修改元素
for ( it = x.cbegin(); it != x.cend(); ++it )//前向迭代
std::cout << ' ' << *it;//*iterator返回迭代器指向的元素
for ( auto it = x.crbegin(); it != x.crend(); ++it )//反向迭代
std::cout << ' ' << *it;//*iterator返回迭代器指向的元素元素修改:
元素的修改可直接利用元素的访问进行直接修改,并且array提供了一键填充的函数fill()以及容器交换的功能swap()。与此同时,
array还提供了元素级的逻辑比较运算符,比如:>,==,<等等,都是要求所有元素都满足逻辑操作才返回true。
2.2 vector
vector是一个多功能的容器,其被创建于堆上,支持所有元素属性,其最大的特点就是动态容器特性,即可以动态调整内存,不过一般每次扩大内存都会比之前大一倍,然后将之前的元素复制到新内存,最后释放原内存。上述所有简单容器的功能vector都具备,用法也类似,所以我这里只介绍其不同的地方。其包含于<vector>头文件之中。
容器创建与初始化:
1
std::vector<int> foo (3,0);//创建一个有3个int元素的容器,并初始化为0
容器属性:
1
2
3
4
5
6
7a.size();//容器大小
a.empty();//容器是否为空
a.resize(5);//调整容器大小为5,不足的初始化为0,多余的去掉,不影响已分配的内存大小
a.resize(5,10);//调整容器大小为5,不足的初始化为10,不影响已分配的内存大小
a.capacity();//容器当前已分配的大小(()单位是元素)
a.reserve(100);//强制调整容器已分配内存元素数量至100
a.shrink_to_fit();//强制调整a.capacity()=a.size()元素调整:
1
2
3
4
5
6
7
8
9
10
11
12a.assign(InputIterator first, InputIterator last);//将另一个容器的first~last位置处的元素赋值给a
a.assign(size_type n, const value_type& val);//赋值n个val值
a.erase(a.begin()+5);//移除a[6]
a.erase(a.begin(),myvector.begin()+3);//移除a[0]~a[3]
a.emplace(a.begin()+1, 100);//在a[0]和a[1]之间插入元素值100,返回当前迭代器a.begin+1
a.emplace_back(100);//在a末尾添加100
a.insert(a.begin()+1,100)//在a[1]之前插入100
a.insert(a.begin(),2,100)//在a[0]处插入两个100
a.insert (a.begin(), src, dst);//将src地址/迭代器到dst的地址/迭代器指向的元素插入到a.begin()处
a.push_back (100);//在末尾添加100
a.pop_back();//移除末尾元素
a.clear();清空容器
3.队列(queue/dequeue)
队列,顾名思义就是遵循先进先出(First in First out, FIFO)原则的线性表结构,在c++的stl标准中也添加了队列结构。其中queue位于头文件<queue>中,用法和原理如下图所示:
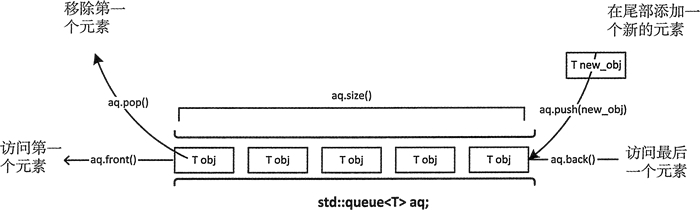
注:初始化不需要定义元素个数,只需要定义元素类型,如:queue<int>q;
当然,随之元素不断的添加,queue很可能会发生内存冲突,因此可以利用queue(int,other)来初始化,其中other代表其它数据类型,一旦被定义,则第一个元素int失效,比如other = std::list<int>代表queue会在遵循FIFO的前提下采用链表存储队列。当然,还可以为其他类型,比如下面要提到的deque:
deque是双端队列,顾名思义其可以在队列的头部以及尾部插入和删除数据,其跟vector的用法很像,不过不同的是deque的动态内存体现在由多个连续的缓冲区组成,并由一块连续内存进行管理:
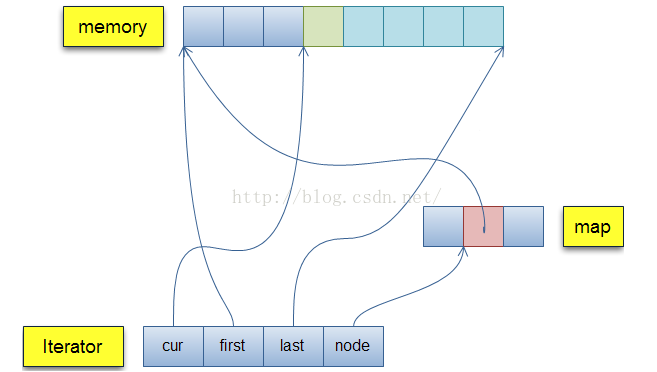
可以看到,map中包含每个缓冲区的节点,每个节点内含有当前缓冲区的中当前元素的指针,当前缓冲区头指针,当前缓冲区尾指针。
deque包含于<deque>头文件中,其绝大多数功能和vector类似,包括元素访问、元素修改等等,比较特殊的就是其添加和去除元素是在队列两端执行的,如:pop_back(),pop_front(),push_back(),push_front()。其初始化方式
4.链表(forawrd_list/list)
链表是一类典型的非连续内存线性表,其包括单向链表(forward_list)和双向列表(list),分别位于同名头文件中。既然是线性表,其自然就具有基本功能,如元素的遍历访问、元素的删除、元素的插入、元素的添加、元素的修改等。二者的创建以及初始化方式相同,不同的就是功能上,单向链表不支持末尾方向的迭代、添加和取出。
初始化方式一般有:
1 | //第一种,构造函数 |
另外,forward_list的元素删除是利用erase_after(),即将迭代器指向位置之后的一个元素删除,而list可以直接利用erase删除当前指向位置。除此之外,链表还提供了以下几个特殊功能:
1 | std::forward_list<int> list1 = {10, 20, 30, 40, 30, 20, 10}; |
还有链表的衔接功能,具体可以去看官网。
5.哈希表和红黑树(map/unordered_map)
map和unordered_map的功能就是实现了类似于字典查询的功能,即<class T1, class T2>的key-value模式,二者都在同名头文件之下,虽然功能一样,但是二者的底层实现完全不同。map采用的是红黑树结构,即一种自平衡的二叉排序树,其查询速度是logn,利用中序遍历方式便利,因此map本身会对元素进行排序。而unordered_map采用的是散列表的结构,散列函数为除留余数法,并利用链地址法防止散列冲突。因此map比unordered_map在时间效率上慢,不过空间占用要少。
二者的功能一致,主要包含:创建、查找、增加、删除、遍历,另外要注意的是,map的排序是默认排序,如果key不是常见的数值元素,最好自定义一个比较函数。
1 | //创建 |
6.集合(set/unordered_set)
集合的特性就是元素的独一性,与上一章类似,set和unordered_set分别采用红黑树和哈希表的方式创建,支持的元素不止基本数据类型,还支持容器。使用方式如下:
1 | //创建 |
7.栈(stack)
栈跟队列很像,不同的就是栈式遵循先进后出(Last in First out, LIFO),功能很简单:
1 | std::stack<int> mystack; |
8.串(string)
字符串(string)与字符数组(char[])很像,从速度上来讲string操作更慢,从操作效率来讲,string更简单,其中string在<string>头文件下,char相关字符操作在<cstring>头文件下。
要注意的是下面两种char数组的区别:
1 | char a[] = "123";//实际存储为{'1', '2', '3', '\0'},strlen(a)=3 |
具体如下:
1 | //创建 |
9.bitset
有时候为了操作的效率以及大数据处理,我们可能会用到数组元素只有{0,1},仅仅占用1bit,不同于bool型的数组,其可以用来做2进制操作,位于同名头文件。
1 | //创建 |

